8 哈夫曼树 3题
sy371: 合并果子
https://sunnywhy.com/sfbj/9/8/371
有 n 堆果子,每堆果子的质量已知,现在需要把这些果子合并成一堆,但是每次只能把两堆果子合并到一起,同时会消耗与两堆果子质量之和等值的体力。显然,在进行 n - 1 次合并之后,就只剩下一堆了。为了尽可能节省体力,需要使耗费的总体力最小。求需要耗费的最小总体力。
输入
第一行一个整数
第二行为用空格隔开的 n 个正整数(每个正整数均不超过100),表示每堆果子的质量。
输出
输出一个整数,表示需要耗费的最小总体力。
样例1
输入
3
1 2 9输出
15解释
先将质量为1的果堆和质量为2的果堆合并,得到质量为3的果堆,同时消耗体力值3;
接着将质量为3的果堆和质量为9的果堆合并,得到质量为12的果堆,同时消耗体力值12;
因此共消耗体力值。
To solve this problem, you can use a priority queue data structure. A priority queue can efficiently insert elements and retrieve the minimum element. In Python, you can use the heapq module to implement a priority queue.
Here is a step-by-step plan:
- Initialize an empty min heap
heap. - For each pile of fruits, insert its weight into the
heap. - While there is more than one pile of fruits, remove the two piles with the smallest weights from the
heap, add their weights together, add the result to the total energy consumption, and insert the result back into theheap. - Print the total energy consumption.
Here is the Python code that implements this plan:
import heapq
n = int(input().strip())
heap = list(map(int, input().strip().split()))
heapq.heapify(heap)
energy = 0
while len(heap) > 1:
a = heapq.heappop(heap)
b = heapq.heappop(heap)
energy += a + b
heapq.heappush(heap, a + b)
print(energy)This code reads the number of piles of fruits and the weights of the piles from the input, inserts each weight into the heap, while there is more than one pile of fruits, removes the two piles with the smallest weights from the heap, adds their weights together, adds the result to the total energy consumption, and inserts the result back into the heap, and then prints the total energy consumption.
sy372: 树的最小带权路径长度
https://sunnywhy.com/sfbj/9/8/372
对一棵 n 个结点的树(结点编号为从0到n-1,根结点为0号结点,每个结点有各自的权值)来说:
- 结点的路径长度是指,从根结点到该结点的边数;
- 结点的带权路径长度是指,结点权值乘以结点的路径长度;
- 树的带权路径长度是指,树的所有叶结点的带权路径长度之和。
现有 n 个不同的正整数,需要寻找一棵树,使得树的所有叶子结点的权值恰好为这 n 个数,并且使得这棵树的带权路径长度是所有可能的树中最小的。求最小带权路径长度。
输入
第一行一个整数
第二行为用空格隔开的 n 个正整数(每个正整数均不超过100),含义如题意所示。
输出
输出一个整数,表示最小带权路径长度。
样例1
输入
3
1 2 9输出
15解释
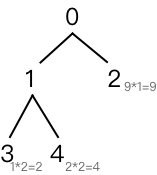
对应最小带权路径长度的树如下图所示,其中黑色数字为结点编号,编号右下角的格式为结点权值*结点路径长度=结点带权路径长度。由此可得树的带权路径长度为,是所有可能的树中最小的。
To solve this problem, you can use a priority queue data structure. A priority queue can efficiently insert elements and retrieve the minimum element. In Python, you can use the heapq module to implement a priority queue.
Here is a step-by-step plan:
- Initialize an empty min heap
heap. - For each weight, insert it into the
heap. - While there is more than one weight in the
heap, remove the two weights with the smallest values from theheap, add them together, add the result to the total weighted path length, and insert the result back into theheap. - Print the total weighted path length.
Here is the Python code that implements this plan:
import heapq
n = int(input().strip())
heap = list(map(int, input().strip().split()))
heapq.heapify(heap)
weighted_path_length = 0
while len(heap) > 1:
a = heapq.heappop(heap)
b = heapq.heappop(heap)
weighted_path_length += a + b
heapq.heappush(heap, a + b)
print(weighted_path_length)This code reads the number of weights from the input, inserts each weight into the heap, while there is more than one weight in the heap, removes the two weights with the smallest values from the heap, adds them together, adds the result to the total weighted path length, and inserts the result back into the heap, and then prints the total weighted path length.
sy373: 最小前缀编码长度
https://sunnywhy.com/sfbj/9/8/373
现需要将一个字符串 s 使用前缀编码的方式编码为 01 串,使得解码时不会产生混淆。求编码出的 01 串的最小长度。
输入
一个仅由大写字母组成、长度不超过的字符串。
输出
输出一个整数,表示最小长度。
样例1
输入
ABBC输出
6解释
将A编码为00,B编码为1,C编码为01,可以得到ABBC的前缀编码串001101,此时达到了所有可能情况中的最小长度6。
解法1:
使用一种基于哈夫曼编码的方法。哈夫曼编码是一种用于无损数据压缩的最优前缀编码方法。简单来说,它通过创建一棵二叉树,其中每个叶节点代表一个字符,每个节点的路径长度(从根到叶)代表该字符编码的长度,来生成最短的编码。字符出现的频率越高,其在树中的路径就越短,这样可以保证整个编码的总长度最小。
首先需要统计输入字符串中每个字符的出现频率。然后,根据这些频率构建哈夫曼树。构建完成后,遍历这棵树以确定每个字符的编码长度。最后,将所有字符的编码长度乘以其出现次数,累加起来,就得到了编码后的字符串的最小长度。
from collections import Counter
import heapq
class HuffmanNode:
def __init__(self, char, freq):
self.char = char
self.freq = freq
self.left = None
self.right = None
# 为了让节点可以在优先队列中被比较,定义比较方法
def __lt__(self, other):
return self.freq < other.freq
def build_huffman_tree(frequencies):
priority_queue = [HuffmanNode(char, freq) for char, freq in frequencies.items()]
heapq.heapify(priority_queue)
while len(priority_queue) > 1:
left = heapq.heappop(priority_queue)
right = heapq.heappop(priority_queue)
merged = HuffmanNode(None, left.freq + right.freq)
merged.left = left
merged.right = right
heapq.heappush(priority_queue, merged)
return priority_queue[0]
def calculate_huffman_code_lengths(node, length=0):
if node is None:
return {}
if node.char is not None:
return {node.char: length}
left_lengths = calculate_huffman_code_lengths(node.left, length + 1)
right_lengths = calculate_huffman_code_lengths(node.right, length + 1)
left_lengths.update(right_lengths)
return left_lengths
def min_encoding_length(s):
frequencies = Counter(s)
huffman_tree = build_huffman_tree(frequencies)
code_lengths = calculate_huffman_code_lengths(huffman_tree)
return sum(frequencies[char] * length for char, length in code_lengths.items())
s = input().strip()
print(min_encoding_length(s))解法2:
To solve this problem, you can use Huffman coding, which is a common algorithm for constructing prefix codes. Huffman coding is a greedy algorithm that uses a priority queue where the node with the lowest probability is given the highest priority.
Here is a step-by-step plan:
- Count the frequency of each character in the string.
- Create a priority queue (min heap) where each node contains a character and its frequency. The priority of a node is determined by its frequency.
- While there is more than one node in the queue:
- Dequeue the two nodes with the highest priority (lowest frequency).
- Create a new node with these two nodes as children and with frequency equal to the sum of the two nodes' frequencies.
- Enqueue the new node.
- The remaining node is the root of the Huffman tree. Traverse the Huffman tree and assign a binary code to each character. The binary code of a character is the path from the root to the character, where going to the left child adds a '0' and going to the right child adds a '1'.
- Replace each character in the string with its binary code. The length of the resulting string is the minimum length of the prefix encoding.
Here is the Python code that implements this plan:
import heapq
from collections import Counter
def huffman_encoding(s):
# Count the frequency of each character
freq = Counter(s)
# Create a priority queue with single node trees
heap = [[weight, [char, ""]] for char, weight in freq.items()]
heapq.heapify(heap)
while len(heap) > 1:
lo = heapq.heappop(heap)
hi = heapq.heappop(heap)
for pair in lo[1:]:
pair[1] = '0' + pair[1]
for pair in hi[1:]:
pair[1] = '1' + pair[1]
heapq.heappush(heap, [lo[0] + hi[0]] + lo[1:] + hi[1:])
huff = sorted(heapq.heappop(heap)[1:], key=lambda p: (len(p[-1]), p))
# Compute the length of the encoded string
length = sum(freq[char] * len(code) for char, code in huff)
return length
s = input().strip()
print(huffman_encoding(s))This code reads a string from the input, counts the frequency of each character, creates a priority queue with single node trees, while there is more than one node in the queue, dequeues the two nodes with the highest priority (lowest frequency), creates a new node with these two nodes as children and with frequency equal to the sum of the two nodes' frequencies, enqueues the new node, the remaining node is the root of the Huffman tree, traverses the Huffman tree and assigns a binary code to each character, replaces each character in the string with its binary code, and then prints the length of the resulting string.