M01577: Falling Leaves
tree, bst, http://cs101.openjudge.cn/practice/01577/
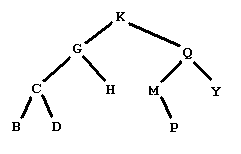 Figure 1 shows a graphical representation of a binary tree of letters. People familiar with binary trees can skip over the definitions of a binary tree of letters, leaves of a binary tree, and a binary search tree of letters, and go right to The problem.
Figure 1 shows a graphical representation of a binary tree of letters. People familiar with binary trees can skip over the definitions of a binary tree of letters, leaves of a binary tree, and a binary search tree of letters, and go right to The problem.
A binary tree of letters may be one of two things:
1.It may be empty.
2.It may have a root node. A node has a letter as data and refers to a left and a right subtree. The left and right subtrees are also binary trees of letters.In the graphical representation of a binary tree of letters:
1.Empty trees are omitted completely.
2.Each node is indicated by
Its letter data,
A line segment down to the left to the left subtree, if the left subtree is nonempty,
A line segment down to the right to the right subtree, if the right subtree is nonempty.A leaf in a binary tree is a node whose subtrees are both empty. In the example in Figure 1, this would be the five nodes with data B, D, H, P, and Y.
The preorder traversal of a tree of letters satisfies the defining properties:
1.If the tree is empty, then the preorder traversal is empty.
2.If the tree is not empty, then the preorder traversal consists of the following, in order
The data from the root node,
The preorder traversal of the root's left subtree,
The preorder traversal of the root's right subtree.The preorder traversal of the tree in Figure 1 is KGCBDHQMPY.
A tree like the one in Figure 1 is also a binary search tree of letters. A binary search tree of letters is a binary tree of letters in which each node satisfies:
The root's data comes later in the alphabet than all the data in the nodes in the left subtree.
The root's data comes earlier in the alphabet than all the data in the nodes in the right subtree.
The problem:
Consider the following sequence of operations on a binary search tree of letters
Remove the leaves and list the data removed Repeat this procedure until the tree is empty Starting from the tree below on the left, we produce the sequence of trees shown, and then the empty tree
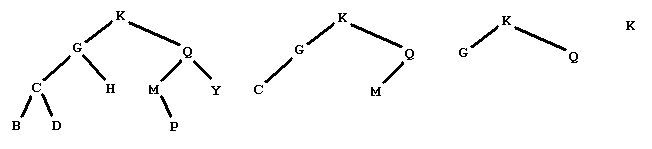
by removing the leaves with data
BDHPY CM GQ K
Your problem is to start with such a sequence of lines of leaves from a binary search tree of letters and output the preorder traversal of the tree.
输入
The input will contain one or more data sets. Each data set is a sequence of one or more lines of capital letters.
The lines contain the leaves removed from a binary search tree in the stages described above. The letters on a line will be listed in increasing alphabetical order. Data sets are separated by a line containing only an asterisk ('*').
The last data set is followed by a line containing only a dollar sign ('$'). There are no blanks or empty lines in the input.
输出
For each input data set, there is a unique binary search tree that would produce the sequence of leaves. The output is a line containing only the preorder traversal of that tree, with no blanks.
样例输入
BDHPY
CM
GQ
K
*
AC
B
$样例输出
KGCBDHQMPY
BAC来源
Mid-Central USA 2000
思路: 事实上,拔掉叶子的顺序即为插入叶子顺序的reversed,并且保证左右顺序由字母表顺序决定,用插入顺序构建出一个树。
class TreeNode:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
def build_bst(leaves):
if not leaves:
return None
root = TreeNode(leaves[0])
for leaf in leaves[1:]:
insert_node(root, leaf)
return root
def insert_node(root, leaf):
if leaf < root.data:
if root.left is None:
root.left = TreeNode(leaf)
else:
insert_node(root.left, leaf)
else:
if root.right is None:
root.right = TreeNode(leaf)
else:
insert_node(root.right, leaf)
def preorder_traversal(root):
if root is None:
return []
traversal = [root.data]
traversal.extend(preorder_traversal(root.left))
traversal.extend(preorder_traversal(root.right))
return traversal
# 读取输入数据
flag = 0
while True:
leaves = []
while True:
line = input().strip()
if line == '*':
break
elif line == '$':
flag = 1
break
else:
leaves.extend(line)
# 构建二叉搜索树
root = build_bst(leaves[::-1])
# 输出前序遍历结果
traversal_result = preorder_traversal(root)
print(''.join(traversal_result))
if flag:
break【段睿瞳 信管系】思路:双单调栈构建笛卡尔树。
利用二叉搜索树(BST)的一个核心性质:中序遍历(Inorder)结果是升序排列的。掌握了所有节点的中序位置(字母排序)和它们在树中的相对深度/优先级(由输入行号决定)时,这个问题就转化为了构建一棵笛卡尔树(Cartesian Tree)。
1. 单调栈构造算法
核心逻辑:
- 中序序列:题目给出的字母是全集,将其按字母表排序,即得到了 BST 的中序遍历。
- 优先级(Height):输入中先出现的行是叶子,后出现的行是父节点。因此,行号越大,优先级越高(越靠近根)。
- 单调栈的作用:
- 对于中序序列中相邻的两个节点
和 : - 如果
的优先级低于 ,说明 可能是 的左子树成员。 - 如果
的优先级高于 ,说明 可能是 的右子树成员。
- 如果
- 左子节点规则:遍历中序序列,当前节点
node会“吞掉”栈中所有比它高度低的节点,最后一个被吞掉的(也就是高度最大且小于node的)就是node的直接左孩子。 - 右子节点规则:反向遍历中序序列,同理可得直接右孩子。
- 对于中序序列中相邻的两个节点
巧妙之处:它通过两次单调栈扫描,一次性确定了所有节点的左右父子关系。这种构造方法的时间复杂度是
2. 代码实现
import sys
class Node:
def __init__(self, data, h):
self.val = data
self.left = None
self.right = None
self.height = h # 这里的 height 代表优先级,行号越大优先级越高
def get_preorder(root):
if not root:
return ""
return root.val + get_preorder(root.left) + get_preorder(root.right)
def process_data(all_nodes):
if not all_nodes:
return
# 1. 按照字母排序,获取中序遍历序列
inorder_nodes = sorted(all_nodes, key=lambda x: x.val)
# 2. 寻找根节点:height 最大的节点是整棵树的根
root = max(all_nodes, key=lambda x: x.height)
# 3. 正向单调栈确定左孩子
# 对于每个节点,它左侧高度比它小的节点中,高度最大的那个是它的左孩子
stack = []
for node in inorder_nodes:
last_popped = None
while stack and stack[-1].height < node.height:
last_popped = stack.pop()
node.left = last_popped
stack.append(node)
# 4. 反向单调栈确定右孩子
# 对于每个节点,它右侧高度比它小的节点中,高度最大的那个是它的右孩子
stack = []
for node in reversed(inorder_nodes):
last_popped = None
while stack and stack[-1].height < node.height:
last_popped = stack.pop()
node.right = last_popped
stack.append(node)
print(get_preorder(root))
def solve():
all_nodes = []
current_height = 0
# 使用 sys.stdin 提高读取效率
lines = sys.stdin.read().splitlines()
for line in lines:
line = line.strip()
if not line: continue
if line == '*' or line == '$':
process_data(all_nodes)
all_nodes = []
current_height = 0
if line == '$':
break
else:
# 记录节点及其所在的行号(高度)
for c in line:
all_nodes.append(Node(c, current_height))
current_height += 1
if __name__ == '__main__':
solve()3. 关键点解读
根节点的确定:使用
max(all_nodes, key=lambda x: x.height)准确找到行号最大(最后输入)的节点作为根。单调栈逻辑:
- 左孩子:在中序遍历中,一个节点的左孩子必须在它的左边。因此,我们正向扫描,当遇到一个高节点时,它左边被它“遮盖”的那些低节点里,最高的那一个是它的直接左孩子。
- 右孩子:同理,反向扫描,一个节点右边被它“遮盖”的低节点里,最高的是它的直接右孩子。
笛卡尔树思想:
- 这种“中序位置+优先级”构建树的方法本质就是构建笛卡尔树。这在处理诸如“范围最值查询(RMQ)”转化为树结构问题时非常经典。
4. 复杂度与优势
- 时间复杂度:
主要消耗在字母排序上(即获取中序序列)。单调栈构造过程是 。 - 空间复杂度:
。 - 优势:这种解法展现了对 BST 结构的深刻理解,即BST 是以 Key 为中序序列、以插入顺序/深度为优先级的笛卡尔树。
【沈俊丞25工院】思路:单调栈做法
本题给出的树是一棵二叉搜索树,给出每个节点的高度而要求还原其前序遍历。 实际上,二叉搜索树条件等于给出了一个中序遍历,因此实际上本题要求由中序遍历和节点高度两个信息求前序遍历。 而凭这两个信息并不能唯一确定一个二叉搜索树。我们不妨直接从这两个信息出发求一个前序遍历,而不经建树。 我们已经知道中序遍历,那么不妨以这个中序遍历出发,看看怎样求前序遍历。 我们考虑题目样例中给的这个中序遍历(前后顺序代表中序遍历顺序,高度代表节点深度): K G Q C M B D H P Y 我们把其前i个数组成的子树的前序遍历写出来: B CB CBD GCBD GCBDH KGCBDH KGCBDHM KGCBDHMP KGCBDHQMP KGCBDHQMPY 我们会发现这样一件事:当我们把中序遍历中的一个新字符加入前序遍历时,如果它的高度小于或等于前一个字符的高度, 那么它会被直接加在字符串的后面;而如果它的高度大于前一个字符的高度,它会被加在前一段字符的前面。 这个“前一段”是由到上一个更高字符的距离所决定的。比如在上例中,当我们把Q加入时,就将Q放在M前。因为M再前一个就是K了。 这很像单调栈的操作方式!只是这里我们的“出栈”实质上变成字符段合并操作了。于是以下是我们的思路: 我们让一个字符代表它左侧连续且高度小于它的字符段。如果右侧出现了一个高度高于它的字符,则这个字符会发动一系列兼并, 更新高度,并且自己排在它所兼并的一系列字符的左边。 比如,还是考虑刚才的题目样例,这个操作就变为(用空格隔开每一组字符串,并且将每一个字符段末尾加上它的高度: B1 <-C2 CB2 <-D1 CB2 D1 <-G3 GCBD3 <-H1 GCBD3 H1 <-K4 KGCBDH4 <-M2 KGCBDH4 M2 <-P1 KGCBDH4 M2 P1 <-Q3 KGCBDH4 QMP3 <-Y1 KGCBDH4 QMP3 Y1 =>KGCBDHQMPY 代码的撰写就简单了。
#单调栈做法
while True:
mat = []
while True:
inp = input()
if inp == "*" : break
if inp == "$" : break
mat.append(inp)
arr = []
for i, li in enumerate(mat):
for ch in li:
arr.append((ch,i))
arr.sort()
stack = []
for ch in arr:
x = ""
while stack and stack[-1][1] < ch[1]:
x = stack.pop()[0] + x
x = ch[0] + x
stack.append((x,ch[1]))
ans = ""
for i in stack:
ans += i[0]
print(ans)
if inp == "$" : break思路中提到了“单调栈做法”。这种做法非常有创意,它通过利用“中序遍历(字母表顺序)+ 节点高度(所在行数)”这两个信息来直接构造前序遍历。在二叉树问题中,如果已知节点的层级和中序位置,确实可以唯一确定一棵树。这种方法在处理大规模数据时效率更高O(N),但在本题字母规模(最多26个)下,标准的 BST 插入法更为直观且易于实现。