第 150 场双周赛-20250215
中国时间:2025-02-15 22:30,1 小时 30 分
https://leetcode.cn/contest/biweekly-contest-150/
3452.好数字之和
https://leetcode.cn/problems/sum-of-good-numbers/
给定一个整数数组 nums 和一个整数 k,如果元素 nums[i] 严格 大于下标 i - k 和 i + k 处的元素(如果这些元素存在),则该元素 nums[i] 被认为是 好 的。如果这两个下标都不存在,那么 nums[i] 仍然被认为是 好的。
返回数组中所有 好 元素的 和。
示例 1:
输入: nums = [1,3,2,1,5,4], k = 2
输出: 12
解释:
好的数字包括 nums[1] = 3,nums[4] = 5 和 nums[5] = 4,因为它们严格大于下标 i - k 和 i + k 处的数字。
示例 2:
输入: nums = [2,1], k = 1
输出: 2
解释:
唯一的好数字是 nums[0] = 2,因为它严格大于 nums[1]。
提示:
2 <= nums.length <= 1001 <= nums[i] <= 10001 <= k <= floor(nums.length / 2)
from typing import List
class Solution:
def sumOfGoodNumbers(self, nums: List[int], k: int) -> int:
good_sum = 0
n = len(nums)
for i in range(n):
is_good = True
# Check if the current element is strictly greater than the element at position i-k
if 0 <= i - k < n and nums[i] <= nums[i - k]:
is_good = False
# Check if the current element is strictly greater than the element at position i+k
if 0 <= i + k < n and nums[i] <= nums[i + k]:
is_good = False
if is_good:
good_sum += nums[i]
return good_sum
if __name__ == "__main__":
solution = Solution()
print(solution.sumOfGoodNumbers([1, 3, 2, 1, 5, 4], 2)) # Output: 12
print(solution.sumOfGoodNumbers([2, 1], 1)) # Output: 2Q2.分割正方形I
https://leetcode.cn/contest/biweekly-contest-150/problems/separate-squares-i/
给你一个二维整数数组 squares ,其中 squares[i] = [xi, yi, li] 表示一个与 x 轴平行的正方形的左下角坐标和正方形的边长。
找到一个最小的 y 坐标,它对应一条水平线,该线需要满足它以上正方形的总面积 等于 该线以下正方形的总面积。
答案如果与实际答案的误差在 10-5 以内,将视为正确答案。
注意:正方形 可能会 重叠。重叠区域应该被 多次计数 。
示例 1:
输入: squares = [[0,0,1],[2,2,1]]
输出: 1.00000
解释:
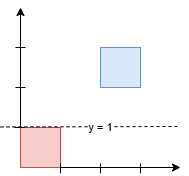
任何在 y = 1 和 y = 2 之间的水平线都会有 1 平方单位的面积在其上方,1 平方单位的面积在其下方。最小的 y 坐标是 1。
示例 2:
输入: squares = [[0,0,2],[1,1,1]]
输出: 1.16667
解释:
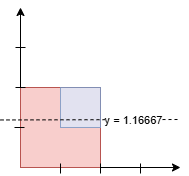
面积如下:
- 线下的面积:
7/6 * 2 (红色) + 1/6 (蓝色) = 15/6 = 2.5。 - 线上的面积:
5/6 * 2 (红色) + 5/6 (蓝色) = 15/6 = 2.5。
由于线以上和线以下的面积相等,输出为 7/6 = 1.16667。
提示:
1 <= squares.length <= 5 * 10^4squares[i] = [xi, yi, li]squares[i].length == 30 <= xi, yi <= 10^91 <= li <= 10^9
我们可以利用这样的观察:对于每个正方形
- 当
时,其贡献为 0; - 当
时,其贡献为 ; - 当
时,其贡献为 ;
记总面积
注意到每个正方形的贡献函数都是连续的、分段线性的,其导数(即“斜率”)在区间内为
具体做法如下:
对于每个正方形
,我们构造两个事件: - 在
时,“开始事件”增加斜率 ; - 在
时,“结束事件”减少斜率 。
- 在
排序时注意:当多个事件发生在同一 y 坐标时,由于正方形在其下边界处贡献 0(还没开始)而在上边界处贡献已满面积,所以顺序无关紧要(也可以先合并同一坐标的所有变化)。
设 f(c) 在区间 [p,q] 内为线性函数,斜率为 S(即当前所有处于“激活”状态的正方形贡献的斜率之和),那么从 p 到 q 面积变化为
;我们从最小事件坐标开始累加,当发现在某个区间内 会从小于 变为大于等于 时,就可以解出满足 即 同时题目要求如果有多个答案,输出最小的 c(也就是区间左端点)。 下面给出完整的 Python 代码(使用 Fraction 保证求解时不会因为大数和除法出现精度问题,最后再转换成浮点数输出 5 位小数误差内的答案):
from fractions import Fraction
from typing import List
class Solution:
def separateSquares(self, squares: List[List[int]]) -> float:
"""
squares[i] = [x, y, l] 表示一个正方形(左下角坐标 (x, y),边长 l)。
返回使得正方形面积被水平线 y=c 分成“线上”和“线下”面积相等的最小 c。
"""
T = 0 # 总面积 = sum(l^2)
events = [] # (y坐标, 斜率变化)
for x, y, l in squares:
T += l * l
events.append((y, l)) # 正方形开始:斜率 +l
events.append((y + l, -l)) # 正方形结束:斜率 -l
# 目标面积 = T/2(用 Fraction 表示)
target = Fraction(T, 2)
# 对事件按 y 坐标排序(相同坐标的事件合并)
events.sort(key=lambda x: (x[0], x[1]))
combined = []
i = 0
n_events = len(events)
while i < n_events:
pos = events[i][0]
delta = 0
while i < n_events and events[i][0] == pos:
delta += events[i][1]
i += 1
combined.append((pos, delta))
# 扫描线:f_val 表示当前累积的面积 f(c),current_slope 表示当前区间的斜率
# 注意:当 c 在一个区间内时,有 f(c) = f_val + current_slope*(c - prev)
prev = combined[0][0] # 从最小的事件坐标开始
f_val = 0 # 此处 f(prev) = 0(因为对于 c 等于最小 y 坐标,每个正方形贡献 0)
current_slope = 0
for pos, delta in combined:
# 在区间 [prev, pos] 内 f(c) = f_val + current_slope*(c - prev)
# 先检查如果 f(prev) 已经正好等于 target,则答案为 prev
if f_val == target:
return float(prev)
if current_slope:
f_next = f_val + current_slope * (pos - prev)
# 如果在本区间内可以达到 target
if f_val < target <= f_next:
# 解出 c: c = prev + (target - f_val) / current_slope
c_sol = Fraction(prev) + Fraction(target - f_val, current_slope)
return float(c_sol)
# 否则累加整个区间
f_val = f_next
# 如果当前斜率为 0,则 f(c) 在 [prev, pos] 上保持不变
current_slope += delta
prev = pos
# 理论上一定能在扫描过程中找到答案
return float(prev)
if __name__ == '__main__':
sol = Solution()
# 示例 1
squares1 = [[0, 0, 1], [2, 2, 1]]
ans1 = sol.separateSquares(squares1)
print("{:.5f}".format(ans1)) # 输出 1.00000
# 示例 2
squares2 = [[0, 0, 2], [1, 1, 1]]
ans2 = sol.separateSquares(squares2)
print("{:.5f}".format(ans2)) # 输出 1.16667说明
构造事件:对于每个正方形,我们在
处加上斜率 (正方形开始后,面积开始线性增加),在 处减去 (正方形“结束”,面积不再增加)。 扫描线求面积:设当前区间起点为 prev ,在区间内斜率为 S(即 current_slope),则区间内面积增加为
;累加得到 。 求解 c:当发现在某个区间内
从 增加到 时跨过目标面积 ,就可以解出 使用 Fraction:保证在计算时不会因为大数或除法导致精度问题,最后将结果转换为 float 输出(误差满足
)。 这种方法的时间复杂度为
(排序事件),对于最多 个正方形(事件数不超过 (10^5) )足够使用。
AI做了个质心的思路,564/914超时了。
[[522261215,954313664,461744743],[628661372,718610752,21844764],[619734768,941310679,91724451],[352367502,656774918,591943726],[860247066,905800565,853111524],[817098516,868361139,817623995],[580894327,654069233,691552059],[182377086,256660052,911357],[151104008,908768329,890809906],[983970552,992192635,462847045]]代码清晰易懂,可惜超时了。
from typing import List
class Solution:
def separateSquares(self, squares: List[List[int]]) -> float:
# 计算总面积(总“质量”)
total_area = sum(l * l for (_, y, l) in squares)
target = total_area / 2.0
# f(c) 返回水平线 y=c 以下的总面积
def f(c: float) -> float:
total = 0.0
for (_, y, l) in squares:
if c <= y:
# 正方形全部在 y=c 之上
continue
elif c >= y + l:
# 正方形全部在 y=c 以下
total += l * l
else:
# 正方形被水平线分割,下部面积为 l*(c-y)
total += l * (c - y)
return total
# 搜索区间:至少从所有正方形的最低边界开始,
# 最大不超过所有正方形的上边界
lo = min(y for (_, y, l) in squares)
hi = max(y + l for (_, y, l) in squares)
# 二分搜索,找到满足 f(c) >= target 的最小 c
eps = 1e-7
while hi - lo > eps:
mid = (lo + hi) / 2.0
if f(mid) < target:
lo = mid
else:
hi = mid
return hi
# ===== 测试样例 =====
if __name__ == "__main__":
sol = Solution()
# 示例 1
squares1 = [[0, 0, 1], [2, 2, 1]]
res1 = sol.separateSquares(squares1)
print("{:.5f}".format(res1)) # 预期输出 1.00000
# 示例 2
squares2 = [[0, 0, 2], [1, 1, 1]]
res2 = sol.separateSquares(squares2)
print("{:.5f}".format(res2)) # 预期输出 1.16667T3454.分割正方形II
线段树, 二分查找, 扫描线, https://leetcode.cn/contest/biweekly-contest-150/problems/separate-squares-ii/
Q4.最短匹配子字符串
https://leetcode.cn/contest/biweekly-contest-150/problems/shortest-matching-substring/
给你一个字符串 s 和一个模式字符串 p,其中 p 恰好 包含 两个 '*' 字符。
p 中的 '*' 匹配零个或多个字符的任何序列。
返回 s 中与 p 匹配的 最短 子字符串的长度。如果没有这样的子字符串,返回 -1。
子字符串 是字符串中的一个连续字符序列(空子字符串也被认为是合法字符串)。
示例 1:
输入: s = "abaacbaecebce", p = "bacce"
输出: 8
解释:
在 s 中,p 的最短匹配子字符串是 "**ba**e**c**eb**ce**"。
示例 2:
输入: s = "baccbaadbc", p = "ccbaaadb"
输出: -1
解释:
在 s 中没有匹配的子字符串。
示例 3:
输入: s = "a", p = "**"
输出: 0
解释:
空子字符串是最短的匹配子字符串。
示例 4:
输入: s = "madlogic", p = "adlogi"
输出: 6
解释:
在 s 中,p 的最短匹配子字符串是 "**adlogi**"。
提示:
1 <= s.length <= 10^52 <= p.length <= 10^5s仅包含小写英文字母。p仅包含小写英文字母,并且恰好包含两个'*'。
下面给出一种思路。注意到模式字符串 (p) 恰好包含两个星号,我们可以将其分割成三个字串:
- (p_1):星号之前的部分
- (p_2):两个星号之间的部分
- (p_3):第二个星号之后的部分
对于一个待选的子串 (T)(连续的一段 (s[i:j])),其匹配要求(因为星号可以匹配任意序列,包括空串)等价于:
- (T) 的开头必须以 (p_1) 开始(如果 (p_1) 非空);
- (T) 内存在一个位置可以匹配 (p_2)(要求 (p_2) 出现在 (T) 中,并且出现在 (p_1) 之后);
- (T) 的结尾必须以 (p_3) 结束(如果 (p_3) 非空)。
为了快速判断某个字串是否出现,我们可以预处理:利用 KMP 算法分别在 (s) 中找出 (p_1,, p_2,, p_3) 的所有出现位置(若某个非空字串在 (s) 中没有出现,则无匹配,答案返回 -1)。
然后,对于一个候选的匹配子串 (T) 如果其起始位置确定为 (i)(对于非空 (p_1) 必须保证 (s[i:i+|p_1|]=p_1);如果 (p_1) 为空,我们可以认为任意 (i) 都可以作为起点),
- 首先设“匹配 (p_1) 后的位置”为 (i_0=i+|p_1|)(如果 (p_1) 为空,则 (i_0=i));
- 如果 (p_2) 非空,则在 (s) 中寻找最早出现的 (p_2)(利用二分查找)其起始位置 (i_1) 满足 (i_1\ge i_0);如果 (p_2) 为空,则可以认为“匹配 (p_2)”发生在位置 (i_0);
- 接下来,如果 (p_3) 非空,则在 (s) 中寻找最早出现的 (p_3)(利用二分查找)其起始位置 (i_2) 满足 (i_2\ge i_1+|p_2|)(注意:当 (p_2) 为空时,则要求 (i_2\ge i_0));此时 (T) 必须至少延伸到位置 (i_2+|p_3|-1);
- 如果 (p_3) 为空,则可以认为 (T) 在匹配完 (p_2) 后结束,即 (T) 至少延伸到位置 (i_1+|p_2|-1)(当 (p_2) 也为空时,则仅需匹配 (p_1))。
候选子串的长度即为
我们枚举所有“合法”的候选起点(对于 (p_1) 非空,就枚举 KMP 求出的出现位置;否则枚举 (s) 中的所有位置),利用二分查找分别在 (p_2) 与 (p_3) 出现位置的列表中找出满足条件的最早位置,然后更新最短子串的长度。若没有任何候选能构成合法匹配,则返回 -1。
下面给出完整 Python 代码:
from bisect import bisect_left
from typing import List
class Solution:
def shortestMatchingSubstring(self, s: str, p: str) -> int:
def kmp_search(text: str, pattern: str) -> List[int]:
"""
返回 pattern 在 text 中所有出现的起始位置(若 pattern 为空,则返回 [0,1,...,len(text)])
"""
if pattern == "":
return list(range(len(text) + 1))
# 构造 lps 数组
m = len(pattern)
lps = [0] * m
j = 0
for i in range(1, m):
while j > 0 and pattern[i] != pattern[j]:
j = lps[j - 1]
if pattern[i] == pattern[j]:
j += 1
lps[i] = j
res = []
j = 0
for i in range(len(text)):
while j > 0 and text[i] != pattern[j]:
j = lps[j - 1]
if text[i] == pattern[j]:
j += 1
if j == m:
res.append(i - m + 1)
j = lps[j - 1]
return res
# 将 p 分成三个部分:p1, p2, p3(恰有两个 '*' )
star_indices = [i for i, ch in enumerate(p) if ch == '*']
if len(star_indices) != 2:
raise ValueError("模式 p 必须恰好包含两个 '*'")
star1, star2 = star_indices
p1 = p[:star1]
p2 = p[star1 + 1:star2]
p3 = p[star2 + 1:]
# 特殊情况:若三个部分均为空,则 p="**",空子串匹配,答案 0
if p1 == "" and p2 == "" and p3 == "":
return 0
n = len(s)
# 预处理:利用 KMP 找出各部分在 s 中出现的所有位置
occ1 = kmp_search(s, p1) if p1 != "" else list(range(n)) # 若 p1 为空,则起点可以选 s 中任意位置
occ2 = kmp_search(s, p2) if p2 != "" else None
occ3 = kmp_search(s, p3) if p3 != "" else None
# 若某个非空部分在 s 中没有出现,则不可能匹配
if p1 != "" and len(occ1) == 0:
return -1
if p2 != "" and len(occ2) == 0:
return -1
if p3 != "" and len(occ3) == 0:
return -1
ans = None
# 枚举候选的子串起始位置 i
for i in occ1:
# 对于 p1 非空,i 已保证 s[i:i+|p1|]==p1;若 p1 为空,则从 i 开始
i0 = i + len(p1) # 匹配完 p1 后的位置
# 处理 p2:
if p2 != "":
# 寻找 occ2 中第一个 >= i0 的位置
pos = bisect_left(occ2, i0)
if pos == len(occ2):
continue # 从 i 出发无法匹配到 p2
i1 = occ2[pos] # p2 在 s 中的起始位置
else:
i1 = i0 # p2 为空,认为匹配发生在 i0
# p2 匹配后结束的位置
i1_end = i1 + len(p2) if p2 != "" else i1
# 处理 p3:
if p3 != "":
# p3 必须出现在 T 中,且起始位置至少不早于 i1_end
pos2 = bisect_left(occ3, i1_end)
if pos2 == len(occ3):
continue
i2 = occ3[pos2] # p3 在 s 中的起始位置
# 子串 T 从 i 到 i2 + |p3| - 1
cur_len = (i2 + len(p3)) - i
else:
# 若 p3 为空,则 T 在匹配完 p2 后结束
# 注意:若 p2 也为空,则 T 仅需要匹配 p1,即 T = s[i : i+|p1|]
if p2 != "":
cur_len = (i1 + len(p2)) - i
else:
cur_len = len(p1) # p1 非空时
if ans is None or cur_len < ans:
ans = cur_len
return ans if ans is not None else -1
# ===== 测试样例 =====
if __name__ == '__main__':
sol = Solution()
# 示例 1
s1 = "abaacbaecebce"
p1 = "ba*c*ce"
res1 = sol.shortestMatchingSubstring(s1, p1)
print("{:.5f}".format(res1)) # 预期 8.00000
# 示例 2
s2 = "baccbaadbc"
p2 = "cc*baa*adb"
res2 = sol.shortestMatchingSubstring(s2, p2)
print(res2) # 预期 -1
# 示例 3
s3 = "a"
p3 = "**"
res3 = sol.shortestMatchingSubstring(s3, p3)
print("{:.5f}".format(res3)) # 预期 0.00000
# 示例 4
s4 = "madlogic"
p4 = "*adlogi*"
res4 = sol.shortestMatchingSubstring(s4, p4)
print("{:.5f}".format(res4)) # 预期 6.00000说明
分解模式
先找出 (p) 中两个'*'的位置,将 p 分为。 KMP 预处理
分别利用 KMP 算法在 s 中查找的所有出现位置(若某非空部分未出现,则无法匹配)。 枚举候选起点
对于候选起点 i(如果非空,候选 i 必须满足 ;否则可枚举所有 i),
利用二分查找依次找到:
- 最早在
处出现 的位置(若 为空则认为匹配在 ); - 再在
匹配后的位置寻找 的出现(若 为空则 T 结束在 匹配结束处)。 计算得到候选子串的长度,并取最小值。
这样就可以在
的时间内求出答案。