P3379 【模板】最近公共祖先(LCA)
LCA, binary lifting, https://www.luogu.com.cn/problem/P3379
给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入
第一行包含三个正整数
接下来
接下来
输出
输出包含
样例
输入 #1
5 5 4
3 1
2 4
5 1
1 4
2 4
3 2
3 5
1 2
4 5输出 #1
4
4
1
4
4说明/提示
对于
对于
对于
样例说明:
该树结构如下:
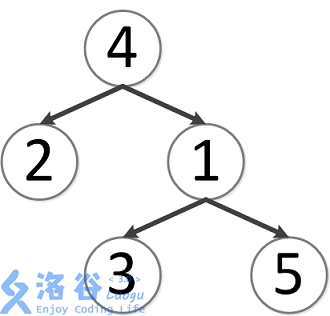
第一次询问:
第二次询问:
第三次询问:
第四次询问:
第五次询问:
故输出依次为
2021/10/4 数据更新 @fstqwq:应要求加了两组数据卡掉了暴力跳。
倍增法,讲的清楚。P3379【模版】最近公共祖先(LCA)
https://www.bilibili.com/video/BV1vg41197Xh?t=856.4
视频讲解,截图:
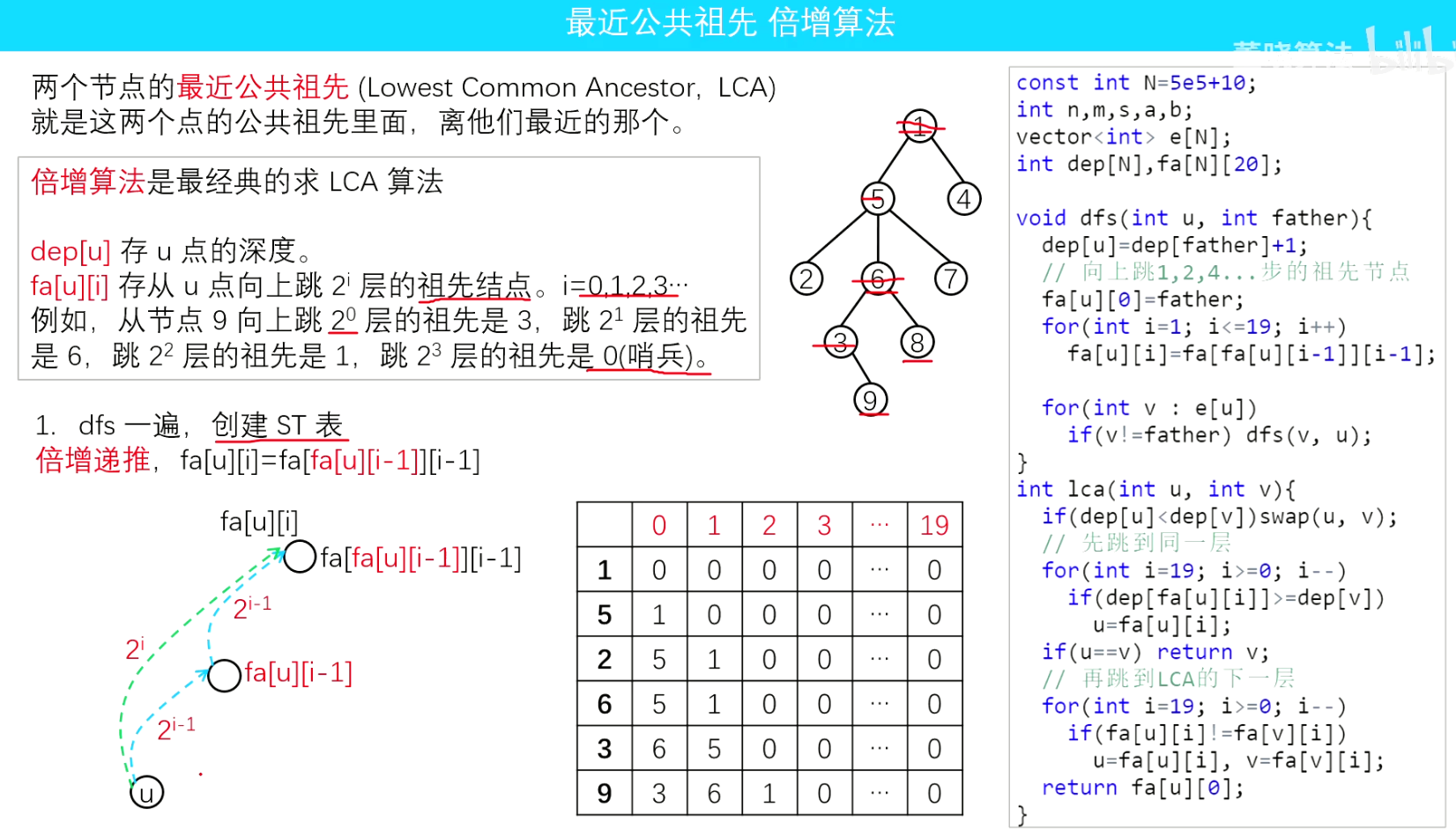

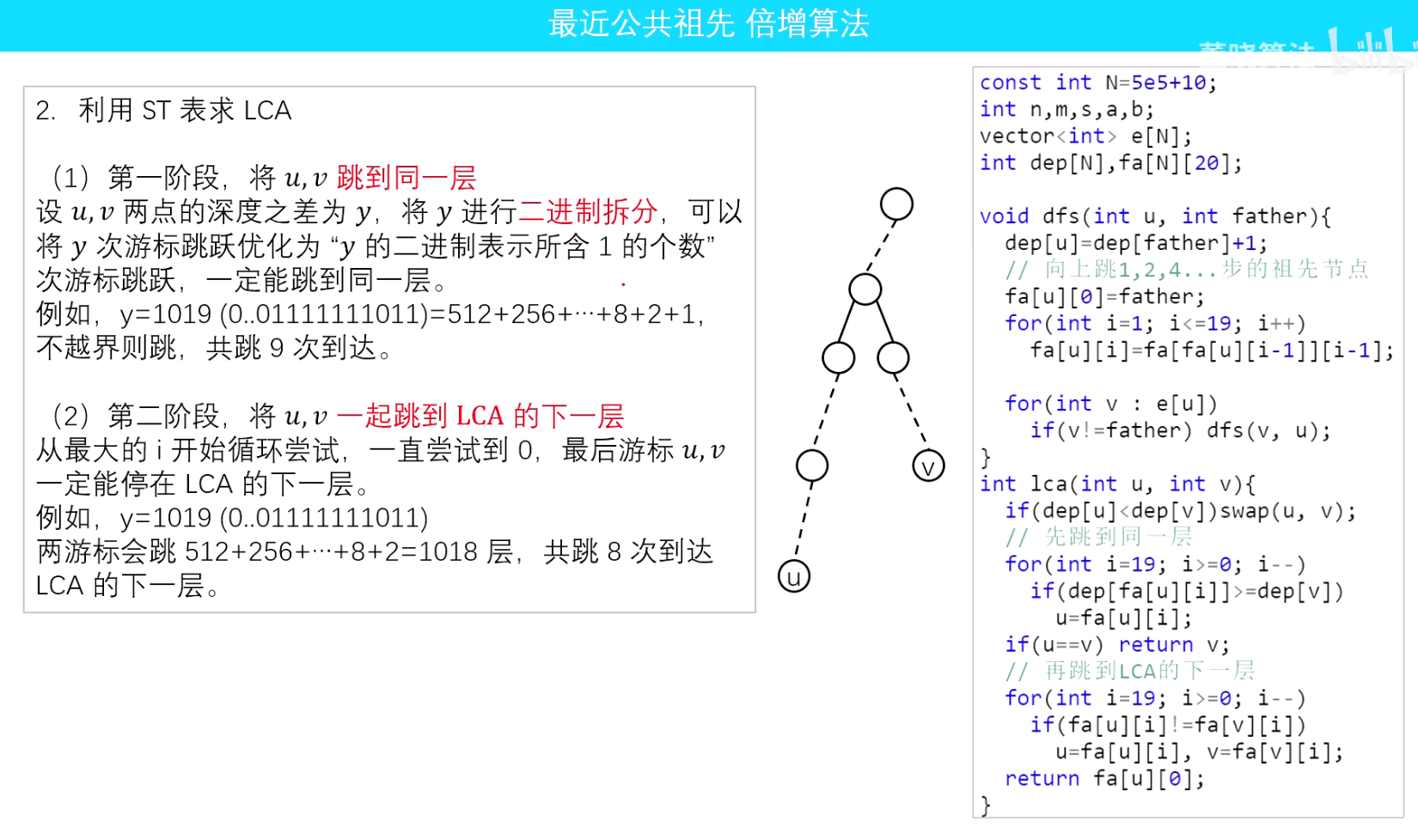
倍增法
对于
在洛谷等 OJ 上,由于 Python 解释器较慢,建议使用以下优化手段:
- 快速输入输出:使用
sys.stdin.read().split()批量读取。 - 迭代式 BFS:代替 DFS,避免递归深度限制并提高深度计算效率。
- 局部变量优化:在函数内部定义变量和逻辑。
- 位运算:利用二进制特性。
Python 代码实现
import sys
def solve():
# 1. 快速读取所有输入数据
# data 将包含所有的 N, M, S, 所有的边, 所有的询问
input_data = sys.stdin.read().split()
if not input_data:
return
it = iter(input_data)
n = int(next(it))
m = int(next(it))
root = int(next(it))
# 2. 建立邻接表
adj = [[] for _ in range(n + 1)]
for _ in range(n - 1):
u = int(next(it))
v = int(next(it))
adj[u].append(v)
adj[v].append(u)
# 3. BFS 预处理深度和父节点
depth = [0] * (n + 1)
parent = [0] * (n + 1)
depth[root] = 1
queue = [root]
# 层次遍历
for u in queue:
for v in adj[u]:
if not depth[v]:
depth[v] = depth[u] + 1
parent[v] = u
queue.append(v)
# 4. 构建倍增表 up[i][u] 表示节点 u 的第 2^i 个祖先
log_n = n.bit_length()
up = [parent] # up[0] 是 2^0 = 1 级祖先
for i in range(1, log_n):
prev_up = up[i-1]
# 使用列表推导式加速
curr_up = [prev_up[prev_up[j]] if prev_up[j] else 0 for j in range(n + 1)]
up.append(curr_up)
# 5. 定义查询函数
# 放在 solve 内部可以利用局部变量加速
results = []
for _ in range(m):
u = int(next(it))
v = int(next(it))
if depth[u] < depth[v]:
u, v = v, u
# 让 u 向上跳到和 v 同一深度
diff = depth[u] - depth[v]
for i in range(log_n):
if (diff >> i) & 1:
u = up[i][u]
if u == v:
results.append(str(u))
continue
# 同时向上跳,跳到 LCA 的下一层
for i in range(log_n - 1, -1, -1):
up_i = up[i]
if up_i[u] != up_i[v]:
u = up_i[u]
v = up_i[v]
results.append(str(up[0][u]))
# 6. 批量输出结果
sys.stdout.write('\n'.join(results) + '\n')
if __name__ == "__main__":
solve()关键点详解
倍增表结构:
up[i][u]这种结构(先索引幂次,再索引节点编号)在 Python 中比up[u][i]快得多。因为在LCA查询的循环中,我们频繁切换节点u,但i是固定或按序变化的。bit_length():这是一个快速获取的二进制位数的方法,用于确定倍增表的最大高度。 对齐深度:
- 先求出深度差
diff。 - 利用二进制拆分,如果
diff的第位是 1,就把 往上跳 步。
- 先求出深度差
二分搜索 LCA:
- 从最大可能的跳跃步数开始尝试(
LOG递减)。 - 如果跳完后两个节点不相等,说明还没跳过头,执行跳跃。
- 最终它们会停在 LCA 的下方,直接返回
up[0][u]即可。
性能说明
对于
的量级,即使使用了倍增法,在 Python3 (CPython) 下运行依然非常吃力(可能会在 1~2s 的时限边缘)。如果是在洛谷等平台提交,建议选择 PyPy 3 编译器,它的 JIT 优化能显著提升循环效率。 如果仍然 TLE,通常需要考虑 Tarjan 离线算法,其时间复杂度为
,在查询量极大时性能优于倍增法。 - 从最大可能的跳跃步数开始尝试(
倍增法,理解了ST 表 (Sparse Table) ,程序就容易看懂了。
在普通数组中,ST 表的递推式是:
st[k][i] = min(st[k-1][i], st[k-1][i + 2^(k-1)])。 在树中,up[k][u]的递推式是:up[k][u] = up[k-1][ up[k-1][u] ]。逻辑相同:都是通过两个 2^{k-1} 的操作合成一个 2^k 的操作。
另外就是AI给的代码,通常是优化的。比如:# 使用列表推导式利用 Python 的 C 语言底层循环,比 for 循环快得多
DFS序 + RMQ (Range Minimum Query)
【孙婧斯、生命科学学院】根据定理,用dfs遍历的树,遍历序在两个节点之间的最浅父节点就是他们的最近共同祖先,最浅父节点的dn值最小。
因此,我们需要记录每个节点的遍历序dn ,st[k] [j]代表遍历序起点为j,长度为2**k的区间中最浅父节点。先把dfs遍历所有节点,赋予dn值,记录直接父节点。然后动态规划推导出st表。查找时,计算区间长度,把区间分为两部分找最小值。
为了避免在最近共同祖先是某个节点本身是错误的输出了他的父节点,区间左端点需要+1
dfn 是 DFS Number。简单来说,dfn 代表了一个节点在进行深度优先搜索(DFS)时被访问到的先后顺序。 dfn = DFS 访问顺序。它是连接“树形结构”与“线性数组”的桥梁。
import sys
def main():
# 1. 快速读取所有输入数据
# data 列表中依次存储了 N, M, S 以及后续的边信息和查询信息
data = list(map(int, sys.stdin.read().split()))
if not data:
return
idx = 0
N = data[idx]; idx += 1 # 节点数
M = data[idx]; idx += 1 # 查询数
S = data[idx]; idx += 1 # 根节点编号
# 2. 建立邻接表(无向图)
# num 设置为 5*10^5 + 1 是为了覆盖题目给定的最大节点范围
MAX_NODE = 5 * 10**5 + 1
graph = [[] for _ in range(MAX_NODE)]
for _ in range(N - 1):
x = data[idx]
y = data[idx + 1]
graph[x].append(y)
graph[y].append(x)
idx += 2
# 3. 预处理相关变量
LOG = 19 # 2^19 > 500,000,用于 ST 表的深度
dfn = [0] * MAX_NODE # 记录每个节点在 DFS 遍历中的访问顺序(时间戳)
# st[k][j] 代表在 DFS 序列中,从位置 j 开始,长度为 2^k 的区间内,dfn 最小的节点的“父节点”
st = [[0] * (N + 1) for _ in range(LOG)]
# 4. 迭代式 DFS(避免 Python 递归深度超限)
# 获取每个节点的 DFN 和 直接父节点
dn = 0 # DFN 计数器
stack = [(S, 0)] # 栈中存储 (当前节点, 父节点)
vis = [False] * MAX_NODE
while stack:
node, father = stack.pop()
if vis[node]:
continue
vis[node] = True
dn += 1
dfn[node] = dn
# 核心逻辑:ST 表的第 0 层存储 DFS 序为 dn 的节点的父节点
st[0][dn] = father
# 遍历子节点(reversed 保持与常规递归顺序一致,非必须)
for child in reversed(graph[node]):
if child != father and not vis[child]:
stack.append((child, node))
# 5. 辅助函数:比较两个节点,返回 dfn 较小的那个节点
def get_min_dfn_node(node_m, node_n):
if node_m == 0: return node_n # 处理边界
if node_n == 0: return node_m
return node_m if dfn[node_m] < dfn[node_n] else node_n
# 6. 动态规划构建 ST 表
# 时间复杂度 O(N log N)
for k in range(1, LOG):
for j in range(1, N - (1 << k) + 2):
# 区间 DP:当前区间最小值由两个子区间最小值合并而来
st[k][j] = get_min_dfn_node(st[k-1][j],
st[k-1][j + (1 << (k-1))])
# 7. LCA 查询函数
# 时间复杂度 O(1)
def query_lca(a, b):
if a == b:
return a
# 转换为 DFS 序进行区间查询
dfn_a, dfn_b = dfn[a], dfn[b]
if dfn_a > dfn_b:
dfn_a, dfn_b = dfn_b, dfn_a
# 【定理关键点】
# LCA(a, b) 是区间 (dfn[a], dfn[b]] 中 dfn 最小的节点的父节点。
# 因此左端点 dfn_a 需要 +1,以排除节点 a 本身。
dfn_a += 1
# 计算区间长度对应的 log 值
length = dfn_b - dfn_a + 1
d = length.bit_length() - 1
# RMQ 查询:取两个重叠区间的最小值
return get_min_dfn_node(st[d][dfn_a],
st[d][dfn_b - (1 << d) + 1])
# 8. 处理查询请求
output = []
for _ in range(M):
u, v = data[idx], data[idx+1]
output.append(str(query_lca(u, v)))
idx += 2
# 9. 批量打印结果,提高效率
sys.stdout.write('\n'.join(output) + '\n')
if __name__ == "__main__":
main()用欧拉序列转化为 RMQ
将 LCA 问题转化为 RMQ 问题是解决树上查询的一种非常高效的在线算法。
核心原理
- 欧拉序列 (Euler Tour):通过 DFS 遍历树,并在进入节点和从子节点返回时都记录该节点。对于一个有
个节点的树,欧拉序列的长度约为 。 - 深度序列:记录欧拉序列中每个位置对应的节点深度。
- 转化逻辑:节点
和 的 LCA,就是欧拉序列中“ 第一次出现的位置”和“ 第一次出现的位置”之间,深度最小的那个节点。 - RMQ 求解:使用 ST 表 (Sparse Table) 预处理深度序列,实现
的区间最小值查询。
复杂度分析
- 时间复杂度:预处理
,查询 。 - 空间复杂度:
,主要用于存储 ST 表。
Python 代码实现 (优化版)
为了处理 array 模块来节省内存,并使用迭代 DFS。
import sys
from array import array
def solve():
# 1. 快速读入
input_data = sys.stdin.read().split()
if not input_data: return
it = iter(input_data)
n = int(next(it))
m = int(next(it))
root = int(next(it))
adj = [[] for _ in range(n + 1)]
for _ in range(n - 1):
u, v = int(next(it)), int(next(it))
adj[u].append(v)
adj[v].append(u)
# 2. 迭代 DFS 生成欧拉序列
# tour_nodes: 记录路径上的节点编号
# tour_depths: 记录对应的深度
# first_pos: 记录每个节点在 tour 中第一次出现的位置
tour_nodes = array('I') # 'I' 是无符号 int
tour_depths = array('I')
first_pos = [-1] * (n + 1)
stack = [(root, -1, 1)] # node, parent, depth
it_map = [0] * (n + 1)
while stack:
u, p, d = stack[-1]
if first_pos[u] == -1:
first_pos[u] = len(tour_nodes)
tour_nodes.append(u)
tour_depths.append(d)
found = False
while it_map[u] < len(adj[u]):
v = adj[u][it_map[u]]
it_map[u] += 1
if v != p:
stack.append((v, u, d + 1))
found = True
break
if not found:
stack.pop()
if stack: # 从子节点回溯,再次记录父节点
pu, pp, pd = stack[-1]
tour_nodes.append(pu)
tour_depths.append(pd)
# 3. 预处理 ST 表 (RMQ)
# st[i][j] 存储 tour_depths 中从 j 开始长度为 2^i 的区间内,最小深度对应的索引
num_tour = len(tour_depths)
log_n = num_tour.bit_length()
# 使用 array 节省内存,st[i] 存储第 i 层幂次的结果
st = [array('I', range(num_tour))]
for i in range(1, log_n):
prev = st[i-1]
step = 1 << (i-1)
# 当前层的大小
curr_len = num_tour - (1 << i) + 1
curr = array('I', [0] * curr_len)
for j in range(curr_len):
idx1 = prev[j]
idx2 = prev[j + step]
if tour_depths[idx1] < tour_depths[idx2]:
curr[j] = idx1
else:
curr[j] = idx2
st.append(curr)
# 4. 在线查询
output = []
for _ in range(m):
u, v = int(next(it)), int(next(it))
l, r = first_pos[u], first_pos[v]
if l > r: l, r = r, l
# 计算区间长度对应的最高幂次
length = r - l + 1
k = length.bit_length() - 1
# 比较两个重叠区间的最小值
idx1 = st[k][l]
idx2 = st[k][r - (1 << k) + 1]
if tour_depths[idx1] < tour_depths[idx2]:
output.append(str(tour_nodes[idx1]))
else:
output.append(str(tour_nodes[idx2]))
sys.stdout.write('\n'.join(output) + '\n')
if __name__ == "__main__":
solve()代码关键点:
- 欧拉序列长度:对于
的树,序列长度约为 。 - 内存管理:Python 的
list存储百万级整数非常耗内存(每个 int 对象约 28 字节)。使用array.array('I', ...)可以将存储开销降低到每个元素 4 字节,防止在大数据下触发内存限制(Memory Limit Exceeded)。 - 迭代 DFS:手动管理
stack以防止 Python 递归溢出。 - ST 表查询:通过
(r - l + 1).bit_length() - 1快速计算。
为什么这个算法被称为“在线”?
因为一旦 solve 中的预处理(ST 表构建)完成,你可以以