T3225.网格图操作后的最大分数
dp, prefix sum, https://leetcode.cn/problems/maximum-score-from-grid-operations/
给你一个大小为 n x n 的二维矩阵 grid ,一开始所有格子都是白色的。一次操作中,你可以选择任意下标为 (i, j) 的格子,并将第 j 列中从最上面到第 i 行所有格子改成黑色。
如果格子 (i, j) 为白色,且左边或者右边的格子至少一个格子为黑色,那么我们将 grid[i][j] 加到最后网格图的总分中去。
请你返回执行任意次操作以后,最终网格图的 最大 总分数。
示例 1:
输入:grid = [[0,0,0,0,0],[0,0,3,0,0],[0,1,0,0,0],[5,0,0,3,0],[0,0,0,0,2]]
输出:11
解释:
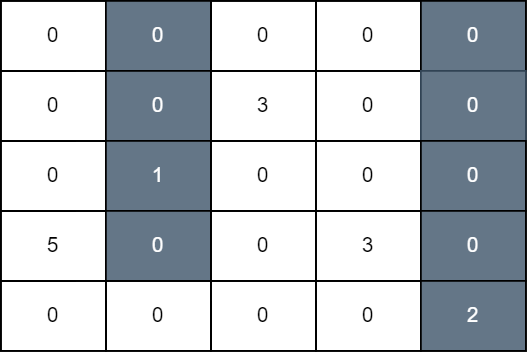
第一次操作中,我们将第 1 列中,最上面的格子到第 3 行的格子染成黑色。第二次操作中,我们将第 4 列中,最上面的格子到最后一行的格子染成黑色。最后网格图总分为 grid[3][0] + grid[1][2] + grid[3][3] 等于 11 。
示例 2:
输入:grid = [[10,9,0,0,15],[7,1,0,8,0],[5,20,0,11,0],[0,0,0,1,2],[8,12,1,10,3]]
输出:94
解释:
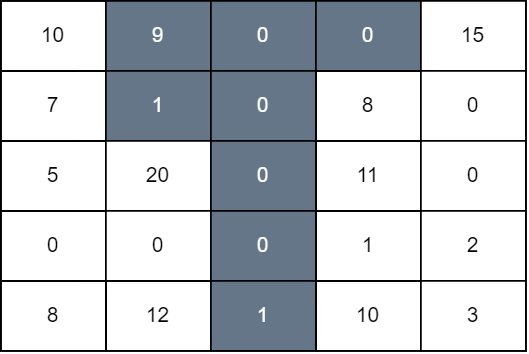
我们对第 1 ,2 ,3 列分别从上往下染黑色到第 1 ,4, 0 行。最后网格图总分为 grid[0][0] + grid[1][0] + grid[2][1] + grid[4][1] + grid[1][3] + grid[2][3] + grid[3][3] + grid[4][3] + grid[0][4] 等于 94 。
提示:
1 <= n == grid.length <= 100n == grid[i].length0 <= grid[i][j] <= 10^9
这个问题可以转化为一个动态规划(DP)问题。
题目核心逻辑
- 染黑操作:对于每一列
,选择一个高度 ,将第 到 行涂黑。 - 得分规则:格子
得分的条件是: - 该格子是白色的(即
)。 - 该格子左边或右边的格子至少有一个是黑色的(即
或 )。 - 总结:第
列的得分区间是 。
- 该格子是白色的(即
算法思路:线性 DP
由于每一列的得分仅取决于它与左右相邻两列的高度关系,我们可以按列顺序进行 DP。
定义
- 状态 0 (递增趋势):
。此时第 列的得分由 决定,分数为第 列中从 到 的格子总和。 - 状态 1 (递减趋势):
。此时第 列的得分由 决定,分数为第 列中从 到 的格子总和。 - 状态 2 (谷底后恢复):前两列处于递减趋势,当前列开始回升(
且 )。在这种情况下,第 列的分数已经在处理 时被计算过了,不需要重复计算。
复杂度分析
- 时间复杂度:
。虽然状态转移涉及高度 和 的比较,但通过维护前缀/后缀最大值,可以将每一层的转移优化到 。 - 空间复杂度:
(预处理前缀和)或 (使用滚动数组优化 DP 状态)。
代码实现
from typing import List
class Solution:
def maximumScore(self, grid: List[List[int]]) -> int:
n = len(grid)
if n == 1:
return 0
# pre[j][k] 表示第 j 列前 k 个元素的前缀和
pre = [[0] * (n + 1) for _ in range(n)]
for j in range(n):
for i in range(n):
pre[j][i+1] = pre[j][i] + grid[i][j]
# f[j][state] 表示当前列高度为 j 时的最大分数
# state 0: 递增, state 1: 递减, state 2: 谷底回升
f = [[-float('inf')] * 3 for _ in range(n + 1)]
# 初始化第 0 列:假设左边有一个高度为 0 的虚拟列,所以是递增态
for j in range(n + 1):
f[j][0] = 0
for i in range(1, n):
new_f = [[-float('inf')] * 3 for _ in range(n + 1)]
# --- 状态 0:递增 (h_i >= h_{i-1}) ---
# 此时第 i-1 列获得分数:pre[i-1][h_i] - pre[i-1][h_{i-1}]
# 优化:new_f[j][0] = max(f[k][0/2] - pre[i-1][k]) + pre[i-1][j] (k <= j)
mx0 = -float('inf')
for j in range(n + 1):
mx0 = max(mx0, f[j][0] - pre[i-1][j], f[j][2] - pre[i-1][j])
new_f[j][0] = mx0 + pre[i-1][j]
# --- 状态 1:递减 (h_i <= h_{i-1}) ---
# 此时第 i 列获得分数:pre[i][h_{i-1}] - pre[i][h_i]
# 优化:new_f[j][1] = max(f[k][0/1/2] + pre[i][k]) - pre[i][j] (k >= j)
mx1 = -float('inf')
for j in range(n, -1, -1):
mx1 = max(mx1, f[j][0] + pre[i][j], f[j][1] + pre[i][j], f[j][2] + pre[i][j])
new_f[j][1] = mx1 - pre[i][j]
# --- 状态 2:谷底回升 (h_i >= h_{i-1}) ---
# 第 i-1 列已经由 h_{i-2} 贡献过分数了,这里不加分
# 优化:new_f[j][2] = max(f[k][1/2]) (k <= j)
mx2 = -float('inf')
for j in range(n + 1):
mx2 = max(mx2, f[j][1], f[j][2])
new_f[j][2] = mx2
f = new_f
return max(max(row) for row in f)关键点解释
- 为什么需要状态 2? 如果
,第 列的得分取决于 。如果我们在递增阶段再次计算 对 的贡献,可能会和 已经提供的贡献产生重叠或逻辑错误。状态 2 允许我们在 增加时,“跳过”对 的重复计分。 - 性能: 由于
,该算法的运行时间非常短(约几毫秒),完全符合题目限制。