T3548.等和矩阵分割 II
prefix sum, https://leetcode.cn/problems/equal-sum-grid-partition-ii/
给你一个由正整数组成的 m x n 矩阵 grid。你的任务是判断是否可以通过 一条水平或一条垂直分割线 将矩阵分割成两部分,使得:
- 分割后形成的每个部分都是 非空
的。 - 两个部分中所有元素的和 相等 ,或者总共 最多移除一个单元格 (从其中一个部分中)的情况下可以使它们相等。
- 如果移除某个单元格,剩余部分必须保持 连通 。
如果存在这样的分割,返回 true;否则,返回 false。
注意: 如果一个部分中的每个单元格都可以通过向上、向下、向左或向右移动到达同一部分中的其他单元格,则认为这一部分是 连通 的。
示例 1:
输入: grid = [[1,4],[2,3]]
输出: true
解释:
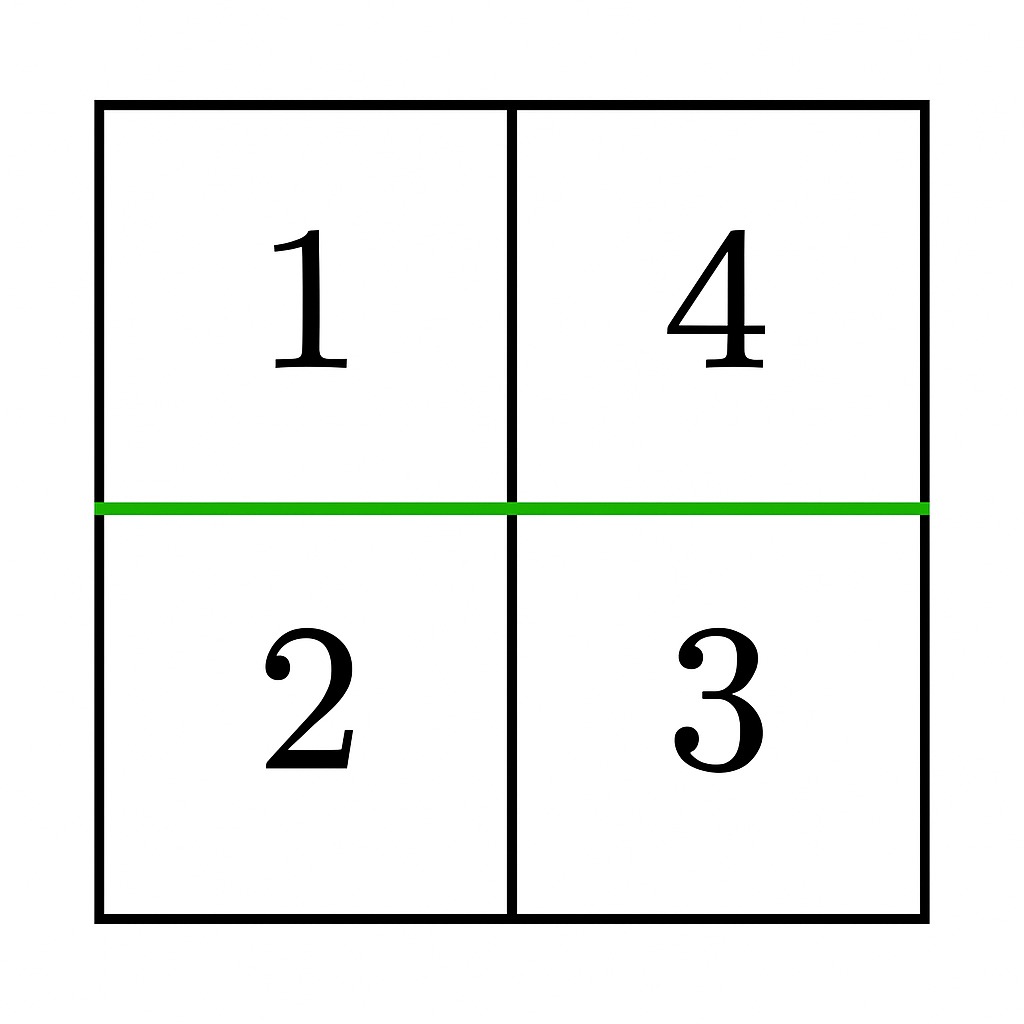
- 在第 0 行和第 1 行之间进行水平分割,结果两部分的元素和为
1 + 4 = 5和2 + 3 = 5,相等。因此答案是true。
示例 2:
输入: grid = [[1,2],[3,4]]
输出: true
解释:
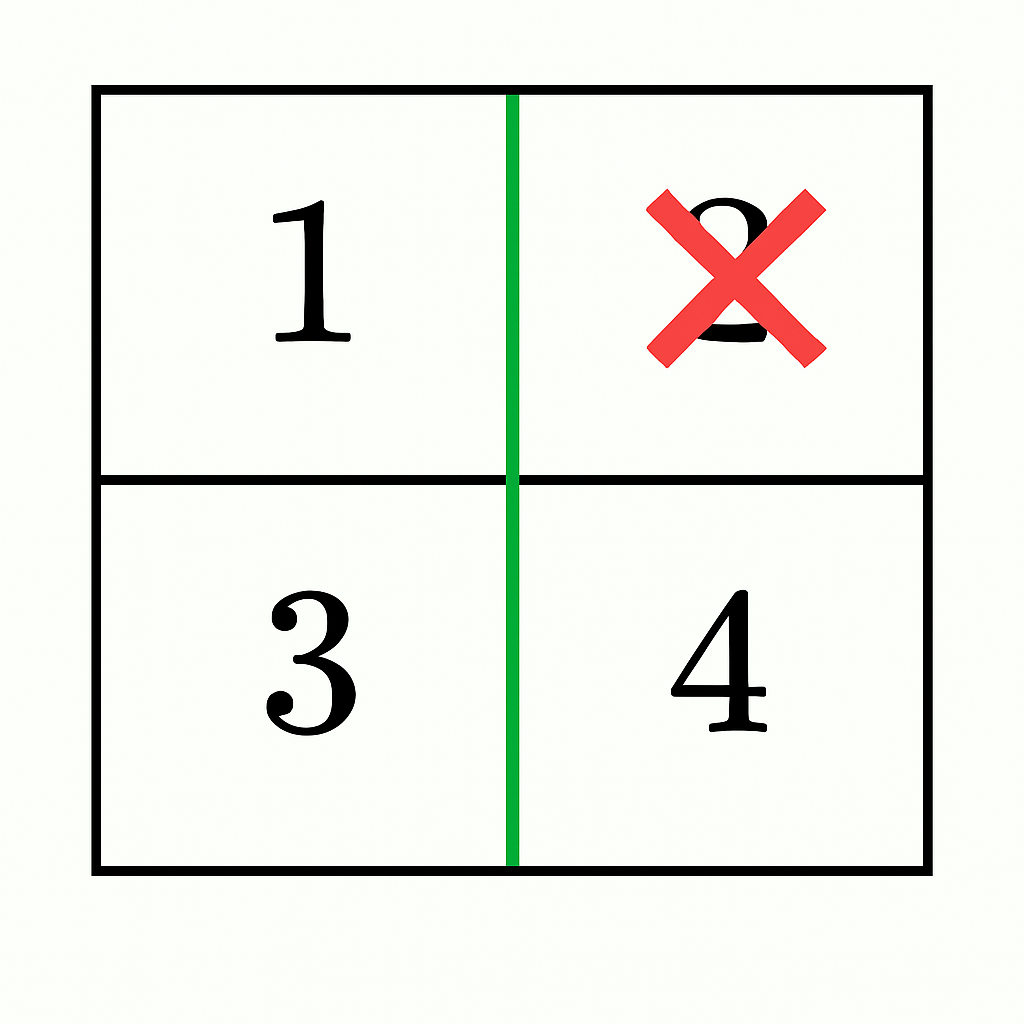
- 在第 0 列和第 1 列之间进行垂直分割,结果两部分的元素和为
1 + 3 = 4和2 + 4 = 6。 - 通过从右侧部分移除
2(6 - 2 = 4),两部分的元素和相等,并且两部分保持连通。因此答案是true。
示例 3:
输入: grid = [[1,2,4],[2,3,5]]
输出: false
解释:
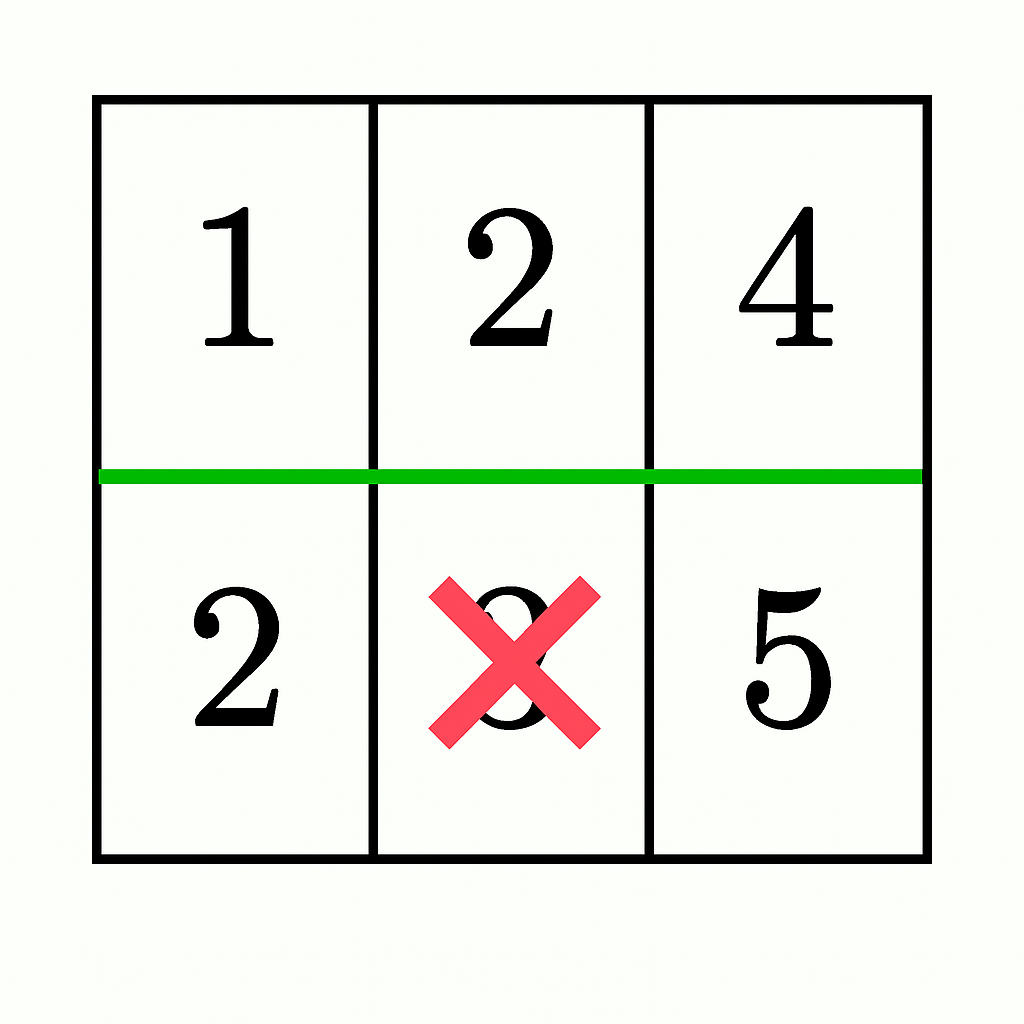
- 在第 0 行和第 1 行之间进行水平分割,结果两部分的元素和为
1 + 2 + 4 = 7和2 + 3 + 5 = 10。 - 通过从底部部分移除
3(10 - 3 = 7),两部分的元素和相等,但底部部分不再连通(分裂为[2]和[5])。因此答案是false。
示例 4:
输入: grid = [[4,1,8],[3,2,6]]
输出: false
解释:
不存在有效的分割,因此答案是 false。
提示:
1 <= m == grid.length <= 10^51 <= n == grid[i].length <= 10^52 <= m * n <= 10^51 <= grid[i][j] <= 10^5
要解决这个问题,我们需要判断是否存在一条水平或垂直分割线,将矩阵分为两部分
。 - 或者在其中一部分中移除一个单元格后,两部分和相等,且剩余部分保持连通。
解题思路
连通性判断: 对于矩形区域(由水平或垂直分割线产生):
- 如果矩形大小为
,且 且 ,移除任何一个单元格后剩余部分仍然是连通的。 - 如果矩形为
(单行),只有移除两端的单元格才能保持连通。 - 如果矩形为
(单列),只有移除顶端或底端的单元格才能保持连通。 - 如果矩形为
,移除唯一的单元格后不再有剩余单元格,但在正整数矩阵中,这会导致另一部分需要等于 0,这是不可能的。
- 如果矩形大小为
前缀和与属性预处理:
- 计算总和
、行和、列和。 - 预处理每个值
在矩阵中出现的最小/最大行号和最小/最大列号。这样可以快速判断某个值 是否存在于特定的矩形部分中。
- 计算总和
枚举分割线:
- 水平分割:枚举第
行后进行分割( )。 为前 行, 为剩余行。 - 垂直分割:枚举第
列后进行分割( )。 为前 列, 为剩余列。 - 对于每种分割,计算
和 。若 ,直接返回 true。否则,计算差值,检查是否存在符合连通性要求的单元格,其值为 。
代码实现
- 水平分割:枚举第
from typing import List
class Solution:
def canPartitionGrid(self, grid: List[List[int]]) -> bool:
m = len(grid)
n = len(grid[0])
row_sums = [0] * m
col_sums = [0] * n
total_sum = 0
# 预处理每个数值在矩阵中出现的边界范围
MAX_VAL = 100000
min_r, max_r = [m] * (MAX_VAL + 1), [-1] * (MAX_VAL + 1)
min_c, max_c = [n] * (MAX_VAL + 1), [-1] * (MAX_VAL + 1)
for r in range(m):
row = grid[r]
row_sum = 0
for c in range(n):
val = row[c]
row_sum += val
col_sums[c] += val
if r < min_r[val]: min_r[val] = r
if r > max_r[val]: max_r[val] = r
if c < min_c[val]: min_c[val] = c
if c > max_c[val]: max_c[val] = c
row_sums[r] = row_sum
total_sum += row_sum
# 检查水平分割
curr_s1 = 0
for i in range(m - 1):
curr_s1 += row_sums[i]
s2 = total_sum - curr_s1
if curr_s1 == s2: return True
if curr_s1 > s2: # 尝试从 P1 (0..i行) 移除 v
v = curr_s1 - s2
if v <= MAX_VAL and min_r[v] <= i:
r_dim, c_dim = i + 1, n
if r_dim > 1 and c_dim > 1: return True
elif r_dim == 1 and c_dim > 1:
if grid[0][0] == v or grid[0][n-1] == v: return True
elif r_dim > 1 and c_dim == 1:
if grid[0][0] == v or grid[i][0] == v: return True
else: # s2 > curr_s1, 尝试从 P2 (i+1..m-1行) 移除 v
v = s2 - curr_s1
if v <= MAX_VAL and max_r[v] >= i + 1:
r_dim, c_dim = m - 1 - i, n
if r_dim > 1 and c_dim > 1: return True
elif r_dim == 1 and c_dim > 1:
if grid[i+1][0] == v or grid[i+1][n-1] == v: return True
elif r_dim > 1 and c_dim == 1:
if grid[i+1][0] == v or grid[m-1][0] == v: return True
# 检查垂直分割
curr_s1 = 0
for j in range(n - 1):
curr_s1 += col_sums[j]
s2 = total_sum - curr_s1
if curr_s1 == s2: return True
if curr_s1 > s2: # 尝试从 P1 (0..j列) 移除 v
v = curr_s1 - s2
if v <= MAX_VAL and min_c[v] <= j:
r_dim, c_dim = m, j + 1
if r_dim > 1 and c_dim > 1: return True
elif r_dim == 1 and c_dim > 1:
if grid[0][0] == v or grid[0][j] == v: return True
elif r_dim > 1 and c_dim == 1:
if grid[0][0] == v or grid[m-1][0] == v: return True
else: # s2 > curr_s1, 尝试从 P2 (j+1..n-1列) 移除 v
v = s2 - curr_s1
if v <= MAX_VAL and max_c[v] >= j + 1:
r_dim, c_dim = m, n - 1 - j
if r_dim > 1 and c_dim > 1: return True
elif r_dim == 1 and c_dim > 1:
if grid[0][j+1] == v or grid[0][n-1] == v: return True
elif r_dim > 1 and c_dim == 1:
if grid[0][j+1] == v or grid[m-1][j+1] == v: return True
return False复杂度分析
- 时间复杂度:
。我们需要遍历矩阵一次来预处理属性,然后分别遍历行和列进行逻辑判断。 - 空间复杂度:
。主要用于存储输入矩阵。辅助数组 min_r等的大小与矩阵内数值范围相关(常数级或),符合题目限制。
from typing import List
import bisect
class Solution:
def canPartitionGrid(self, grid: List[List[int]]) -> bool:
m, n = len(grid), len(grid[0])
total = sum(sum(row) for row in grid)
# Compute row and column sums
row_sum = [sum(r) for r in grid]
col_sum = [sum(grid[i][j] for i in range(m)) for j in range(n)]
# Build maps: value -> sorted unique rows, value -> sorted unique cols
row_map = {}
col_map = {}
for i in range(m):
for j in range(n):
v = grid[i][j]
if v not in row_map:
row_map[v] = []
col_map[v] = []
# append unique row
if not row_map[v] or row_map[v][-1] != i:
row_map[v].append(i)
# append unique col
if not col_map[v] or col_map[v][-1] != j:
col_map[v].append(j)
# Helper: check if any x in sorted arr lies in [a,b]
def in_range(arr, a, b):
i = bisect.bisect_left(arr, a)
return i < len(arr) and arr[i] <= b
# Try horizontal splits
prefix = 0
for i in range(m - 1):
prefix += row_sum[i]
rest = total - prefix
if prefix == rest:
return True
diff = abs(prefix - rest)
# Determine larger region rows [a..b] and width w
if prefix > rest:
a, b = 0, i
else:
a, b = i + 1, m - 1
h = b - a + 1
w = n
# If both dims >=2: can remove any matching cell
if h >= 2 and w >= 2:
if diff in row_map and in_range(row_map[diff], a, b):
return True
# Single row region
elif h == 1 and w >= 2:
r0 = a
if grid[r0][0] == diff or grid[r0][n - 1] == diff:
return True
# Single column region
elif h >= 2 and w == 1:
c0 = 0
if grid[a][c0] == diff or grid[b][c0] == diff:
return True
# Try vertical splits
prefix = 0
for j in range(n - 1):
prefix += col_sum[j]
rest = total - prefix
if prefix == rest:
return True
diff = abs(prefix - rest)
# Determine larger region cols [a..b] and height h
if prefix > rest:
a, b = 0, j
else:
a, b = j + 1, n - 1
w = b - a + 1
h = m
# If both dims >=2
if h >= 2 and w >= 2:
if diff in col_map and in_range(col_map[diff], a, b):
return True
# Single column region
elif w == 1 and h >= 2:
c0 = a
if grid[0][c0] == diff or grid[m - 1][c0] == diff:
return True
# Single row region (m==1)
elif h == 1 and w >= 2:
r0 = 0
if grid[r0][a] == diff or grid[r0][b] == diff:
return True
return FalseI’ve replaced the brute-force cell scans with value-to-row/col maps plus binary searches. This cuts down each split check to O(log k) instead of O(region size), so the overall complexity becomes O(m · n + (m + n) log (m · n)). Let me know if you hit any edge-case issues!