第 437 场周赛-20250216
中国时间:2025-02-16 10:30 1 小时 30 分
https://leetcode.cn/contest/weekly-contest-437/
3456.找出长度为K的特殊子字符串
https://leetcode.cn/problems/find-special-substring-of-length-k/
给你一个字符串 s 和一个整数 k。
判断是否存在一个长度 恰好 为 k 的子字符串,该子字符串需要满足以下条件:
- 该子字符串 只包含一个唯一字符(例如,
"aaa"或"bbb")。 - 如果该子字符串的 前面 有字符,则该字符必须与子字符串中的字符不同。
- 如果该子字符串的 后面 有字符,则该字符也必须与子字符串中的字符不同。
如果存在这样的子串,返回 true;否则,返回 false。
子字符串 是字符串中的连续、非空字符序列。
示例 1:
输入: s = "aaabaaa", k = 3
输出: true
解释:
子字符串 s[4..6] == "aaa" 满足条件:
- 长度为 3。
- 所有字符相同。
- 子串
"aaa"前的字符是'b',与'a'不同。 - 子串
"aaa"后没有字符。
示例 2:
输入: s = "abc", k = 2
输出: false
解释:
不存在长度为 2 、仅由一个唯一字符组成且满足所有条件的子字符串。
提示:
1 <= k <= s.length <= 100s仅由小写英文字母组成。
class Solution:
def hasSpecialSubstring(self, s: str, k: int) -> bool:
n = len(s)
for i in range(n - k + 1):
if len(set(s[i:i + k])) == 1:
if i > 0 and s[i - 1] == s[i]:
continue
if i + k < n and s[i + k] == s[i]:
continue
return True
return False
if __name__ == "__main__":
sol = Solution()
print(sol.hasSpecialSubstring("aaabaaa", 3))
print(sol.hasSpecialSubstring("abc", 2))3457.吃披萨
https://leetcode.cn/problems/eat-pizzas/
给你一个长度为 n 的整数数组 pizzas,其中 pizzas[i] 表示第 i 个披萨的重量。每天你会吃 恰好 4 个披萨。由于你的新陈代谢能力惊人,当你吃重量为 W、X、Y 和 Z 的披萨(其中 W <= X <= Y <= Z)时,你只会增加 1 个披萨的重量!体重增加规则如下:
- 在 奇数天(按 1 开始计数)你会增加
Z的重量。 - 在 偶数天,你会增加
Y的重量。
请你设计吃掉 所有 披萨的最优方案,并计算你可以增加的 最大 总重量。
注意:保证 n 是 4 的倍数,并且每个披萨只吃一次。
示例 1:
输入: pizzas = [1,2,3,4,5,6,7,8]
输出: 14
解释:
- 第 1 天,你吃掉下标为
[1, 2, 4, 7] = [2, 3, 5, 8]的披萨。你增加的重量为 8。 - 第 2 天,你吃掉下标为
[0, 3, 5, 6] = [1, 4, 6, 7]的披萨。你增加的重量为 6。
吃掉所有披萨后,你增加的总重量为 8 + 6 = 14。
示例 2:
输入: pizzas = [2,1,1,1,1,1,1,1]
输出: 3
解释:
- 第 1 天,你吃掉下标为
[4, 5, 6, 0] = [1, 1, 1, 2]的披萨。你增加的重量为 2。 - 第 2 天,你吃掉下标为
[1, 2, 3, 7] = [1, 1, 1, 1]的披萨。你增加的重量为 1。
吃掉所有披萨后,你增加的总重量为 2 + 1 = 3。
提示:
4 <= n == pizzas.length <= 2 * 10^51 <= pizzas[i] <= 10^5n是 4 的倍数。
我们可以这样思考:
将所有 (n=4m) 个披萨分成两类:
- 轻的:作为每组的“填充披萨”(filler),不贡献体重增加;
- 重的:作为每组中“计入增重的披萨”。
每组必定有 4 个披萨,且按从小到大记为
其中: - 奇数天的增重取 Z(组中最大);
- 偶数天的增重取 Y(组中第二大)。
因此,对于奇数天,我们只需要一个重披萨;而偶数天必须“牺牲”出两个重披萨:一份作为“大披萨”(不计入增重,仅起“撑场面”作用),另一份才算 bonus。
设:
为天数, 偶数天数, (也就是 )。
每天的披萨数分配要求:
- 奇数天:1 重披萨(计入增重) + 3 填充披萨;
- 偶数天:2 重披萨(其中较小的计入增重,较大的只用于凑组) + 2 填充披萨。
所以,所有天的填充披萨总数为
而“重披萨”总数为 由于我们希望获得尽可能多的 bonus(计入增重),自然希望“重披萨”尽可能大,而“填充披萨”尽可能小。因此最佳做法是:
排序后分组:先将所有披萨按从小到大排序。
取前
个作为填充披萨;剩下的 (R) 个披萨(必然是较重的)作为“重披萨”集合 (H)。 在 (H) 中:
- 奇数天直接取一个 bonus(全取其值);
- 偶数天需要从 (H) 中选出 一对,其中较大(support)不计入增重,较小(bonus)计入增重。
我们如何选择偶数天的这对?注意:(H) 中共有
个元素,我们必须为偶数天选出 对,即共 个元素;而剩下的 个自然分配给奇数天作为 bonus。 为了使 bonus 总和最大(等价于使被牺牲的“support”总和尽可能小),一个简单的贪心策略是:
- 将 (H) 保持从小到大的顺序;
- 从 (H) 中最小的
个中,相邻配对(即 (H[0]) 和 (H[1]) 为一对,(H[2]) 和 (H[3]) 为一对,…),在每一对中后者作为 support。
那么当天总增重为:
【
【完整代码如下:】
from typing import List
class Solution:
def maxWeight(self, pizzas: List[int]) -> int:
"""
输入:披萨重量数组,长度 n(n 为 4 的倍数)
输出:吃完所有披萨后,能够增加的最大总重量
"""
n = len(pizzas)
m = n // 4
m_even = m // 2 # 偶数天数
m_odd = m - m_even # 奇数天数(等价于 ceil(m/2))
# 每个奇数天需要 3 个填充披萨,每个偶数天需要 2 个填充披萨
filler_count = 3 * m_odd + 2 * m_even
# 排序后,最轻的 filler_count 个作为填充披萨,剩下的作为“重披萨”
pizzas.sort() # 从小到大排序
heavy = pizzas[filler_count:] # 这部分披萨用于计入增重(重披萨)
total_heavy = sum(heavy)
# 偶数天需要从 heavy 中配对出 2*m_even 个披萨:
# 在每一对中,较大的披萨用于撑场面(不计入增重),较小的披萨计入 bonus
# 由于 heavy 已排序,从最小的 2*m_even 个中,每隔一个取出的即为 bonus
support_sum = sum(heavy[1:2 * m_even:2])
return total_heavy - support_sum
if __name__ == "__main__":
sol = Solution()
print(sol.maxWeight([1, 2, 3, 4, 5, 6, 7, 8]))
print(sol.maxWeight([2, 1, 1, 1, 1, 1, 1, 1]))
print(sol.maxWeight([3,4,2,4,2,4,2,2,4,5,3,2,1,2,1,1]))【说明】
- 关键在于将披萨分为“填充”与“重披萨”两部分,且保证偶数天配对时“支持披萨”(较大那个)尽可能轻,以便“bonus”能尽可能大。
- 时间复杂度:排序 (O(n\log n)),对于 (n\le 2\times10^5) 足够。
3458.选择K个互不重叠的特殊子字符串
https://leetcode.cn/problems/select-k-disjoint-special-substrings/
给你一个长度为 n 的字符串 s 和一个整数 k,判断是否可以选择 k 个互不重叠的 特殊子字符串 。
特殊子字符串 是满足以下条件的子字符串:
- 子字符串中的任何字符都不应该出现在字符串其余部分中。
- 子字符串不能是整个字符串
s。
注意:所有 k 个子字符串必须是互不重叠的,即它们不能有任何重叠部分。
如果可以选择 k 个这样的互不重叠的特殊子字符串,则返回 true;否则返回 false。
子字符串 是字符串中的连续、非空字符序列。
示例 1:
输入: s = "abcdbaefab", k = 2
输出: true
解释:
- 我们可以选择两个互不重叠的特殊子字符串:
"cd"和"ef"。 "cd"包含字符'c'和'd',它们没有出现在字符串的其他部分。"ef"包含字符'e'和'f',它们没有出现在字符串的其他部分。
示例 2:
输入: s = "cdefdc", k = 3
输出: false
解释:
最多可以找到 2 个互不重叠的特殊子字符串:"e" 和 "f"。由于 k = 3,输出为 false。
示例 3:
输入: s = "abeabe", k = 0
输出: true
提示:
2 <= n == s.length <= 5 * 10^40 <= k <= 26s仅由小写英文字母组成。
下面给出一种基于“候选区间”枚举,再贪心选择互不重叠区间的解法。
思路
特殊子字符串的定义:
一个子字符串 T=s[i:j](记作区间 ([i,j]),下标均包含)是特殊的,当且仅当对于其中的每个字符 (c),在整个字符串 (s) 中所有的 (c) 都出现在区间 ([i,j]) 内。另外,(T) 不能等于整个 (s)。
关键观察:
如果某个字符只在 (s) 中出现一次,则对应单个字符构成的子字符串一定特殊。
如果 (T) 中包含重复字符,比如 (c) 出现多次,那么为了保证“(c) 在 (s) 中只出现在 (T) 内”,必须包含 (c) 在 (s) 中的所有出现位置。
由(2)可知,对于重复字符 (c),如果要构成特殊子字符串,必须选择从 (c) 的第一次出现开始的一个区间;因为如果从后面开始,那么前面的 (c) 落在 (T) 之外。
因此,我们考虑这样的候选区间:
- 候选产生方式: 对于每个下标 (i) 满足 (i==\mathtt{first_occ}[s[i]])(即该位置是字母第一次出现),我们“贪心扩张”得到最小区间 ([i,j]) 满足:
- 对于区间中任一位置 (t\in[i,j]) 都有 (\mathtt{first_occ}[s[t]]\ge i)(也就是说,区间内每个字母的所有出现都在区间内),
- 扩张时令 (j=\max_{t\in[i,j]}(\mathtt{last_occ}[s[t]]));当 (j) 不再增大时停下。
- 如果得到的区间恰好为整个字符串(即 (i=0) 且 (j=n-1)),则不能选。
- 对于只出现一次的字符(例如 (s[i]) 唯一),因为 (i==\mathtt{first_occ}[s[i]]) 且 (\mathtt{last_occ}[s[i]]=i),候选区间即为 ([i,i])。
最后: 得到候选区间集合后,我们用标准的“区间调度”贪心算法选出最多个不重叠的区间,看是否至少能选出 (k) 个。
代码
- 候选产生方式: 对于每个下标 (i) 满足 (i==\mathtt{first_occ}[s[i]])(即该位置是字母第一次出现),我们“贪心扩张”得到最小区间 ([i,j]) 满足:
class Solution:
def maxSubstringLength(self, s: str, k: int) -> bool:
n = len(s)
# k==0 时,不选任何子串,总是满足要求
if k == 0:
return True
# 预处理:统计每个字符第一次和最后一次出现的位置
first_occ = {}
last_occ = {}
for i, ch in enumerate(s):
if ch not in first_occ:
first_occ[ch] = i
last_occ[ch] = i
# 对于下标 i,如果 i 是 s[i] 的第一次出现,
# 则尝试扩张得到候选区间 [i, j](保证区间内每个字符在 s 中首次出现位置均不小于 i)
def get_candidate(i: int):
j = last_occ[s[i]]
while True:
new_j = j
for t in range(i, j + 1):
# 若区间内某个字符 c 的第一次出现在 i 之前,则该区间无效
if first_occ[s[t]] < i:
return None
new_j = max(new_j, last_occ[s[t]])
if new_j == j:
break
j = new_j
return (i, j)
candidates = []
for i in range(n):
if i == first_occ[s[i]]:
cand = get_candidate(i)
if cand is not None:
# 排除整个 s 作为候选
if not (cand[0] == 0 and cand[1] == n - 1):
candidates.append(cand)
# 采用贪心区间调度:先按结束位置排序,再依次选取互不重叠的区间
candidates.sort(key=lambda interval: interval[1])
count = 0
current_end = -1
for start, end in candidates:
if start > current_end:
count += 1
current_end = end
return count >= k
if __name__ == '__main__':
sol = Solution()
print(sol.maxSubstringLength("abcdbaefab", 2)) # 输出 True
print(sol.maxSubstringLength("cdefdc", 3)) # 输出 False
print(sol.maxSubstringLength("abeabe", 0)) # 输出 True
print(sol.maxSubstringLength("gaixgqpgdrhhxuurgrriwovkbjjbffnlnjcnyzbmblymcmvnftlpaiqepgxgiperurhgduaqpqxqgaxdexur", 6))说明
- 预处理阶段:我们记录了每个字母的首次和最后出现位置。
- 候选区间生成:仅对“首次出现”的位置 (i) 进行扩张,过程中检查若遇到区间内某字符 (c) 的首次出现位置小于 (i),则说明 (c) 在 (i) 之前也出现过,故该候选区间不满足特殊子字符串条件。
- 贪心调度:对所有候选区间按结束位置排序,依次选择不重叠的区间,看是否至少有 (k) 个。
这种方法时间复杂度主要在预处理 (O(n)) 和候选区间扩张上(候选个数至多 26,每个扩张扫描区间长度不超过 (n)),整体效率适用于
希望这个解法能满足题目要求!
3459.最长V形对角线段的长度
https://leetcode.cn/problems/length-of-longest-v-shaped-diagonal-segment/
给你一个大小为 n x m 的二维整数矩阵 grid,其中每个元素的值为 0、1 或 2。
V 形对角线段 定义如下:
线段从
1开始。后续元素按照以下无限序列的模式排列:
2, 0, 2, 0, ...。该线段:
- 起始于某个对角方向(左上到右下、右下到左上、右上到左下或左下到右上)。
- 沿着相同的对角方向继续,保持 序列模式 。
- 在保持 序列模式 的前提下,最多允许 一次顺时针 90 度转向 另一个对角方向。
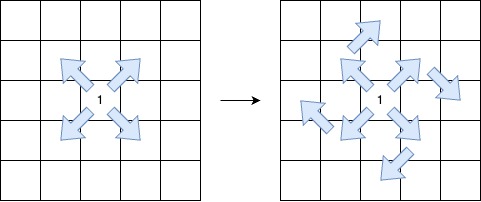
返回最长的 V 形对角线段 的 长度 。如果不存在有效的线段,则返回 0。
示例 1:
输入: grid = [[2,2,1,2,2],[2,0,2,2,0],[2,0,1,1,0],[1,0,2,2,2],[2,0,0,2,2]]
输出: 5
解释:
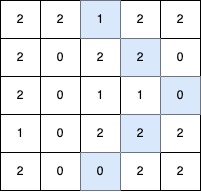
最长的 V 形对角线段长度为 5,路径如下:(0,2) → (1,3) → (2,4),在 (2,4) 处进行 顺时针 90 度转向 ,继续路径为 (3,3) → (4,2)。
示例 2:
输入: grid = [[2,2,2,2,2],[2,0,2,2,0],[2,0,1,1,0],[1,0,2,2,2],[2,0,0,2,2]]
输出: 4
解释:
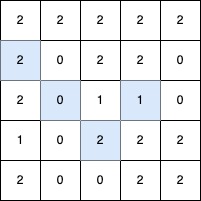
最长的 V 形对角线段长度为 4,路径如下:(2,3) → (3,2),在 (3,2) 处进行 顺时针 90 度转向 ,继续路径为 (2,1) → (1,0)。
示例 3:
输入: grid = [[1,2,2,2,2],[2,2,2,2,0],[2,0,0,0,0],[0,0,2,2,2],[2,0,0,2,0]]
输出: 5
解释:
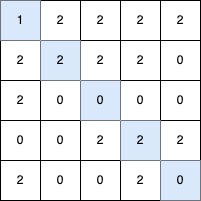
最长的 V 形对角线段长度为 5,路径如下:(0,0) → (1,1) → (2,2) → (3,3) → (4,4)。
示例 4:
输入: grid = [[1]]
输出: 1
解释:
最长的 V 形对角线段长度为 1,路径如下:(0,0)。
提示:
n == grid.lengthm == grid[i].length1 <= n, m <= 500grid[i][j]的值为0、1或2。
下面给出一种思路——将一条 V‐形线段拆分为两个“斜线段”,其中第一个“斜线段”必须从一个 1 开始并严格按序列 (1,2,0,2,0,…)延伸(我们用“链”表示),第二个“斜线段”同样必须延续后面的序列。唯一的“转折点”即为两个斜线段的交界处,它既是第一个斜线段的终点,又是(转向后)第二个斜线段前进前的“分界点”(注意:转向时不重复该格)。
具体做法分为两大部分:
【第一段(不转向部分)】
对于任一斜线方向(共有 4 个对角方向),定义“链结束值” ep——即沿该方向上(从某个起点开始,要求第一个数字必须为 1)能够构成的最长【连续】链(链内数字必须依次为:- 第1个必须为 1;
- 此后交替:奇数位置应为 2,偶数位置(从第2个开始)应为 0)。
我们用动态规划求出对于每个方向 d,在合适的遍历顺序下,对于每个格子 (r,c) 能否作为【链的末尾】以及该链长度是多少。递推关系为:
对于 (r,c) 可“单独启动”一个链:若 grid[r][c]==1,则候选长度为 1。
若 (r,c) 的“前驱格”为 (r–dr, c–dc)(即同一斜线上紧靠前面的格子)存在且已能形成一条链,设其长度为 L,则如果
- L 为奇(即链中最后一个数字为 1→2转换后期望为 2),则要求 grid[r][c]==2;
- L 为偶(即上一步链为 “…2” 后期望 0),则要求 grid[r][c]==0;
满足则 (r,c) 可延长链,其长度为 L+1。
这样,对于每个方向 d,我们得到一个二维数组 ep_d,记录每个格子能作为该方向链末尾时的链长(若不能构成则为 0)。同时【直链】(不转向)的最大长度即为所有 ep_d 中的最大值。
【转向后第二段】
规定转向“只能顺时针 90°”——即若第一段沿方向 d,则转向后必须沿方向 d2 = (d+1) mod 4。转向时,假设第一段在某格 (r,c)结束,其链长度为 L1,那么下一个格(第二段的起点)必须是 (r+dr2, c+dc2)(注意:不重复 (r,c)),且要求该格的数字应符合序列中下一个数字。观察序列可知:- 若 L1 为奇,则第一段最后数字下标为 L1–1 为奇(例如:链长 3 得到序列 [1,2,0]),下一个位置下标 L1 为偶,期望数字为 2(因为从 1 开始,奇数位置给 2);
- 若 L1 为偶,则下一个期望数字为 0。
同样,我们预先对【第二段】做一个“从起点出发沿某方向走能形成的链长度”动态规划,但这次状态只有两种(因为序列除开第一个固定的 1,其余交替:奇位——2,偶位——0)。设 dp[d][s] 为在方向 d 内,从某格开始(该格即为第二段起点)能走出的最长链,其中 s 表示“当前期望状态”:
- s==1 表示期望数字为 2,
- s==2 表示期望数字为 0,
转换关系为:若当前位置 (r,c) 的数字等于期望值,则 dp[d][s][r][c] = 1 + dp[d][next(s)][r+dr][c+dc](其中 next(1)=2,next(2)=1),否则为 0。注意,为保证“后继格子”已算好,需要按“逆向遍历”(不同方向的遍历顺序不同)。
【枚举组合】
对每个方向 d(作为第一段方向),对于每个格子 (r,c)(在 ep_d 中值不为 0 的即为一个可能的转折点,第一段长度 L1 = ep_d[r][c]),尝试转向。新方向 d2 = (d+1)%4,新段起点为 (r+dr2, c+dc2);若该格在范围内,则第二段能走出的长度为 dp_turn[d2][s][...],其中 s = 1 当 L1 为奇,s = 2 当 L1 为偶。总 V 形长度 candidate = L1 +(第二段长度)。答案取直链最大值与所有 candidate 的最大值。下面给出完整 Python 代码(代码中注释较详细):
def longestVShape(grid):
n = len(grid)
m = len(grid[0])
# 四个对角方向,按顺时针顺序排列
# d0: (1,1) ——从左上到右下
# d1: (1,-1) ——从右上到左下
# d2: (-1,-1) ——从右下到左上
# d3: (-1,1) ——从左下到右上
dirs = [(1, 1), (1, -1), (-1, -1), (-1, 1)]
# 预处理第一段:对于每个方向 d,计算 ep_d[r][c] 表示:沿方向 d、以某起点(要求第一个数字为 1)出发,
# 能否构成一条满足序列 [1, 2, 0, 2, 0, ...] 的【连续】链,并且 (r,c) 为该链的终点,其链长是多少。
def compute_ep(d):
dr, dc = d
ep = [[0]*m for _ in range(n)]
# 根据方向确定遍历顺序
if dr == 1 and dc == 1: # d0
r_range = range(n)
c_range = range(m)
elif dr == 1 and dc == -1: # d1
r_range = range(n)
c_range = range(m-1, -1, -1)
elif dr == -1 and dc == -1: # d2
r_range = range(n-1, -1, -1)
c_range = range(m-1, -1, -1)
elif dr == -1 and dc == 1: # d3
r_range = range(n-1, -1, -1)
c_range = range(m)
else:
r_range = range(n)
c_range = range(m)
for r in r_range:
for c in c_range:
cand = 1 if grid[r][c] == 1 else 0 # 新起点
pr, pc = r - dr, c - dc
if 0 <= pr < n and 0 <= pc < m and ep[pr][pc] > 0:
L = ep[pr][pc]
# 若前一段链长度为 L,则其下一位应为:
# 若 L 为奇:期望 2;若 L 为偶:期望 0
if L % 2 == 1:
if grid[r][c] == 2:
cand = max(cand, L + 1)
else:
if grid[r][c] == 0:
cand = max(cand, L + 1)
ep[r][c] = cand
return ep
# 预处理第二段:对每个方向 d,我们计算 dp_turn[d][s] (s取值 1或2)
# dp_turn[d][s][r][c] 表示:在方向 d 上,从 (r,c) 出发,若当前期望状态为 s,
# 能走出的最大链长。这里 s==1 表示期望数字 2;s==2 表示期望数字 0。
# 转换关系:若当前位置 (r,c) 的数字等于预期值,则 dp[r][c] = 1 + dp[next_state] 在下一格,否则为 0。
# 其中 next_state: next(1)=2, next(2)=1.
def compute_dp_turn(d):
dr, dc = d
dp1 = [[0]*m for _ in range(n)] # 状态 1:期待 2
dp2 = [[0]*m for _ in range(n)] # 状态 2:期待 0
# 根据 d 确定逆向遍历顺序(使得 (r+dr, c+dc) 已经计算好)
if dr == 1 and dc == 1: # d0: 下一格是 (r+1, c+1) ->逆序:r 从 n-1 到 0, c 从 m-1 到 0
r_range = range(n-1, -1, -1)
c_range = range(m-1, -1, -1)
elif dr == 1 and dc == -1: # d1: 下一格 (r+1, c-1) -> r: n-1->0, c: 0->m-1
r_range = range(n-1, -1, -1)
c_range = range(m)
elif dr == -1 and dc == -1: # d2: 下一格 (r-1, c-1) -> r: 0->n-1, c: 0->m-1
r_range = range(n)
c_range = range(m)
elif dr == -1 and dc == 1: # d3: 下一格 (r-1, c+1) -> r: 0->n-1, c: m-1->0
r_range = range(n)
c_range = range(m-1, -1, -1)
else:
r_range = range(n-1, -1, -1)
c_range = range(m-1, -1, -1)
for r in r_range:
for c in c_range:
# 状态 1:期望数字 2
if grid[r][c] == 2:
nr, nc = r + dr, c + dc
if 0 <= nr < n and 0 <= nc < m:
dp1[r][c] = 1 + dp2[nr][nc]
else:
dp1[r][c] = 1
else:
dp1[r][c] = 0
# 状态 2:期望数字 0
if grid[r][c] == 0:
nr, nc = r + dr, c + dc
if 0 <= nr < n and 0 <= nc < m:
dp2[r][c] = 1 + dp1[nr][nc]
else:
dp2[r][c] = 1
else:
dp2[r][c] = 0
return dp1, dp2
# 预先计算四个方向的 ep 和 dp_turn
ep_list = [] # ep_list[d] 为方向 d 的 ep 数组
dp_turn_list = [] # dp_turn_list[d] = (dp1, dp2) 对于方向 d
for d in range(4):
ep_list.append(compute_ep(dirs[d]))
dp_turn_list.append(compute_dp_turn(dirs[d]))
ans = 0
# 第一,直链(不转向)的最大长度
for d in range(4):
for r in range(n):
# 注意遍历整行
cur_max = max(ep_list[d][r])
if cur_max > ans:
ans = cur_max
# 第二,枚举转向:对于每个方向 d(第一段方向),对于每个可能的转折点 (r,c)
# 设第一段长度 L1 = ep_list[d][r][c] > 0,则转向后的方向 d2 = (d+1)%4,
# 转段起点为 (r + dr2, c + dc2)。此时第二段必须从状态:
# if L1 为奇,则下一个应期待 2,对应状态 1;
# if L1 为偶,则下一个应期待 0,对应状态 2.
for d in range(4):
dr, dc = dirs[d]
d2 = (d + 1) % 4
dr2, dc2 = dirs[d2]
dp1_d2, dp2_d2 = dp_turn_list[d2] # 对于第二段方向 d2
ep_d = ep_list[d]
for r in range(n):
for c in range(m):
L1 = ep_d[r][c]
if L1 <= 0:
continue
# 转向点:位于 (r, c);转段起点为 (r2, c2)
r2, c2 = r + dr2, c + dc2
if not (0 <= r2 < n and 0 <= c2 < m):
continue
# 根据 L1 奇偶决定第二段起点所用 dp 状态:
# L1 奇 →下一期待为 2 →状态 1;L1 偶 →期待 0 →状态 2.
if L1 & 1:
L2 = dp1_d2[r2][c2]
else:
L2 = dp2_d2[r2][c2]
candidate = L1 + L2
if candidate > ans:
ans = candidate
return ans
# ------------------ 测试样例 ------------------
if __name__ == '__main__':
# 示例 1
grid1 = [
[2,2,1,2,2],
[2,0,2,2,0],
[2,0,1,1,0],
[1,0,2,2,2],
[2,0,0,2,2]
]
print(longestVShape(grid1)) # 预期 5
# 示例 2
grid2 = [
[2,2,2,2,2],
[2,0,2,2,0],
[2,0,1,1,0],
[1,0,2,2,2],
[2,0,0,2,2]
]
print(longestVShape(grid2)) # 预期 4
# 示例 3
grid3 = [
[1,2,2,2,2],
[2,2,2,2,0],
[2,0,0,0,0],
[0,0,2,2,2],
[2,0,0,2,0]
]
print(longestVShape(grid3)) # 预期 5
# 示例 4
grid4 = [[1]]
print(longestVShape(grid4)) # 预期 1说明
第一段 DP(函数 compute_ep)
根据当前方向 d,按照能够保证“前驱已算好”的顺序(例如 d0 时 r 从上到下,c 从左到右),递推计算每个格子能作为链尾的最大链长。第二段 DP(函数 compute_dp_turn)
同样根据方向 d,按逆向遍历顺序计算。从某格出发,如果格内数字与“当前期望”(状态 1:2,状态 2:0)匹配,则能延伸 1+下一格(状态互换)。组合枚举
遍历每个方向 d 的每个格子作为第一段的终点(转折点),如果该处链长 L1>0,则转向(固定为顺时针 90°,即 d2=(d+1)%4)后,在转段起点处查 dp_turn 得到第二段长度 L2,总长度 = L1+L2。同时也考虑不转向(直链)的情况。这种方法整体时间复杂度大约 O(8×n×m)(每个方向各遍历一次),对于 n,m≤500 足够。
希望这个解法能够满足题目要求!