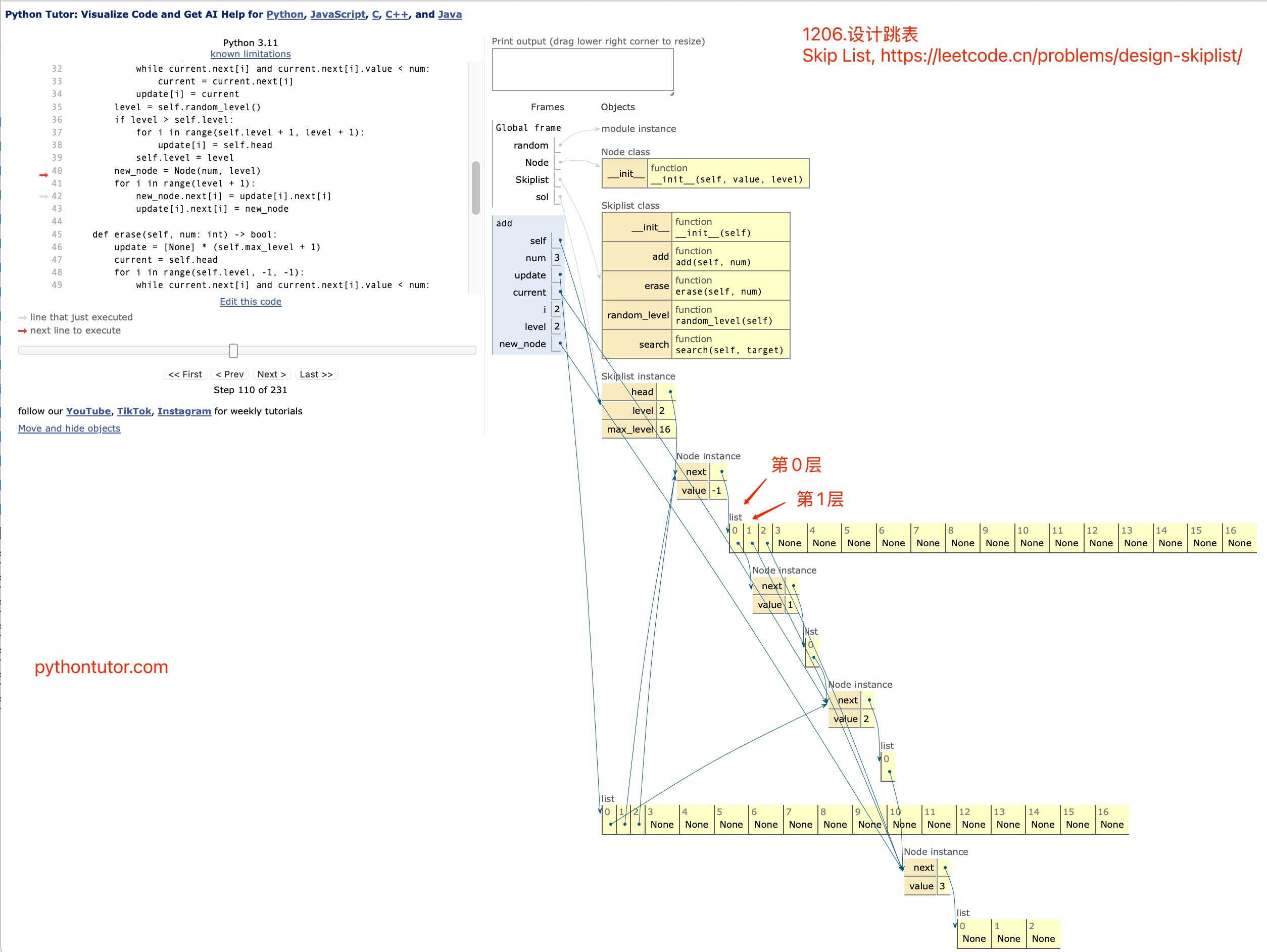
1206.设计跳表
Skip List, https://leetcode.cn/problems/design-skiplist/
不使用任何库函数,设计一个 跳表 。
跳表 是在 O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。跳表相比于树堆与红黑树,其功能与性能相当,并且跳表的代码长度相较下更短,其设计思想与链表相似。
例如,一个跳表包含 [30, 40, 50, 60, 70, 90] ,然后增加 80、45 到跳表中,以下图的方式操作:
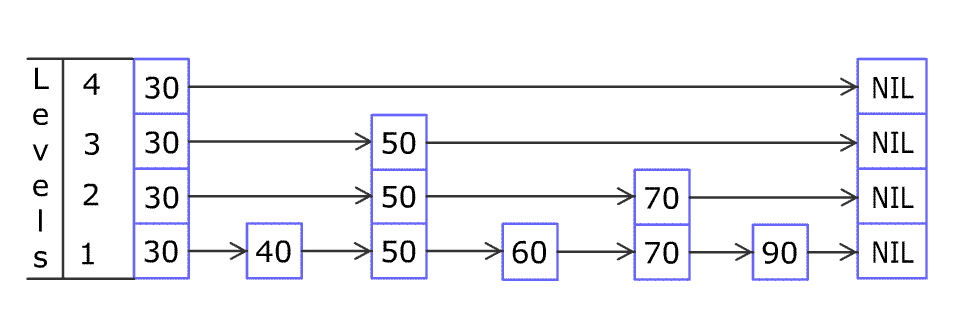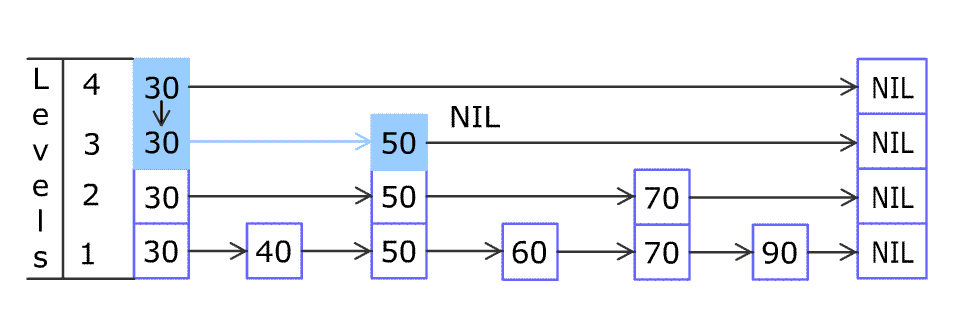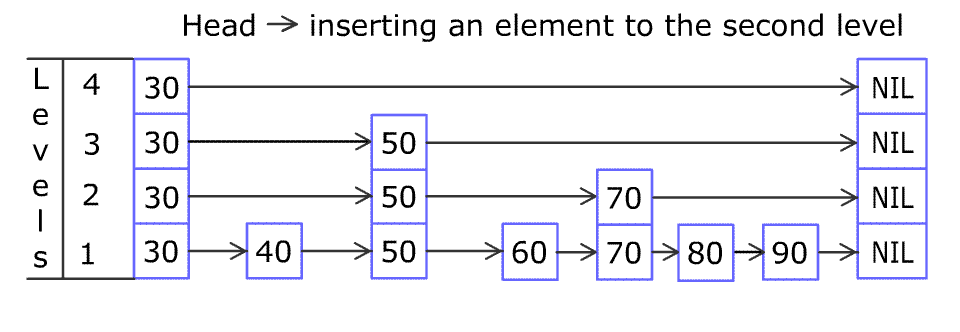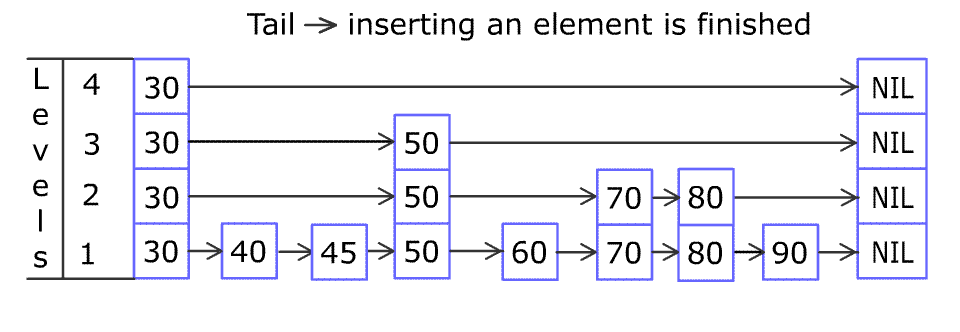
跳表中有很多层,每一层是一个短的链表。在第一层的作用下,增加、删除和搜索操作的时间复杂度不超过 O(n)。跳表的每一个操作的平均时间复杂度是 O(log(n)),空间复杂度是 O(n)。
了解更多 : https://oi-wiki.org/ds/skiplist/
在本题中,你的设计应该要包含这些函数:
bool search(int target): 返回target是否存在于跳表中。void add(int num): 插入一个元素到跳表。bool erase(int num): 在跳表中删除一个值,如果num不存在,直接返回false. 如果存在多个num,删除其中任意一个即可。
注意,跳表中可能存在多个相同的值,你的代码需要处理这种情况。
示例 1:
输入
["Skiplist", "add", "add", "add", "search", "add", "search", "erase", "erase", "search"]
[[], [1], [2], [3], [0], [4], [1], [0], [1], [1]]
输出
[null, null, null, null, false, null, true, false, true, false]
解释
Skiplist skiplist = new Skiplist();
skiplist.add(1);
skiplist.add(2);
skiplist.add(3);
skiplist.search(0); // 返回 false
skiplist.add(4);
skiplist.search(1); // 返回 true
skiplist.erase(0); // 返回 false,0 不在跳表中
skiplist.erase(1); // 返回 true
skiplist.search(1); // 返回 false,1 已被擦除提示:
0 <= num, target <= 2 * 10^4- 调用
search,add,erase操作次数不大于5 * 10^4
跳表这种数据结构是由William Pugh发明的。跳表是一种随机化的数据结构,可以被看做二叉树的一个变种,它在性能上和红黑树、AVL树不相上下,但是跳表的原理非常简单,目前在Redis和LevelDB中都有用到。跳表的期望空间复杂度为O(n),跳表的查询,插入和删除操作的期望时间复杂度均为O(logn)。跳表实际为一种多层的有序链表,跳表的每一层都为一个有序链表,且满足每个位于第i层的节点有p的概率出现在第i+1层,其中p为常数。
为什么要随机? 跳表通过随机层数来平衡链表长度和查找效率,使得插入/删除操作的时间复杂度保持在 O(logn) 的概率期望内。
对于单链表而言,所有的操作(增删改查)都遵循「先查找,再操作」的步骤,这导致在单链表上所有操作复杂度均为O(n)(瓶颈在于查找过程)。
跳表相对于单链表,则是通过引入「多层」链表来优化查找过程,其中每层链表均是「有序」链表:
对于单链表的Node设计而言,我们只需存储对应的节点值val,以及当前节点的下一节点的指针
对于跳表来说,除了存储对应的节点值val以外,我们需要存储当前节点在「每一层」的下一节点指针
跳表的level编号从下往上递增,最下层的链表为元素最全的有序单链表,而查找过程则是按照level从上往下进行。
作者:宫水三叶 链接:https://leetcode.cn/problems/design-skiplist/solutions/1698876/by-ac_oier-38rd/
https://runestone.academy/ns/books/published/pythonds3/Advanced/DictionariesRevisited.html
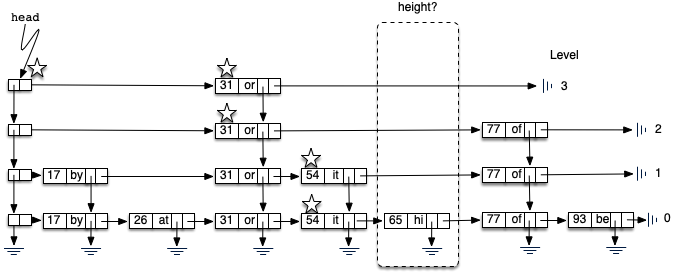
新建一个数据节点,并将它加到第0层的链表中,如下图所示。然而,如果止步于此,最多只能得到一个键值对链表。我们还需要为新的数据节点构建塔,这就是跳表的有趣之处。塔应该多高?新数据节点的塔高并不是确定的,而是完全随机的。本质上,通过“抛硬币”来决定是否要往塔中加一层。如果得到正面,就往当前的塔中加一层。
import random
class Node:
def __init__(self, value, level):
self.value = value
self.next = [None] * (level + 1)
class Skiplist:
def __init__(self):
self.max_level = 16 # 限制最大层数
self.head = Node(-1, self.max_level) # 头节点
self.level = 0 # 当前跳表的层数
def random_level(self):
level = 0
while random.random() < 0.5 and level < self.max_level:
level += 1
return level
def search(self, target: int) -> bool:
current = self.head
for i in range(self.level, -1, -1):
while current.next[i] and current.next[i].value < target:
current = current.next[i]
current = current.next[0]
return current is not None and current.value == target
def add(self, num: int) -> None:
update = [None] * (self.max_level + 1)
current = self.head
for i in range(self.level, -1, -1):
while current.next[i] and current.next[i].value < num:
current = current.next[i]
update[i] = current
level = self.random_level()
if level > self.level:
for i in range(self.level + 1, level + 1):
update[i] = self.head
self.level = level
new_node = Node(num, level)
for i in range(level + 1):
new_node.next[i] = update[i].next[i]
update[i].next[i] = new_node
def erase(self, num: int) -> bool:
update = [None] * (self.max_level + 1)
current = self.head
for i in range(self.level, -1, -1):
while current.next[i] and current.next[i].value < num:
current = current.next[i]
update[i] = current
current = current.next[0]
if current is None or current.value != num:
return False
for i in range(self.level + 1):
if update[i].next[i] != current:
break
update[i].next[i] = current.next[i]
while self.level > 0 and self.head.next[self.level] is None:
self.level -= 1
return True
if __name__ == "__main__":
sol = Skiplist()
sol.add(1)
sol.add(2)
sol.add(3)
print(sol.search(0)) # False
sol.add(4)
print(sol.search(1)) # True
print(sol.erase(0)) # False
print(sol.erase(1)) # True
print(sol.search(1)) # False理解跳表(Skiplist)的实现原理和每个方法的具体作用。
在跳表中,通过随机数决定每个节点的层数,从而达到平衡的效果。
节点类:
Nodepythonclass Node: def __init__(self, value, level): self.value = value self.next = [None] * (level + 1)
属性解释:
value:存储节点的值。next:一个列表,表示在不同层次上的后继节点指针。列表长度为level + 1(因为层数从 0 开始计数),每个位置存储相应层级上的下一个节点的引用,初始时都为None。作用:每个
Node实例代表跳表中的一个节点,其next数组用来连接同一层中的下一个节点,构成多层的链表结构。跳表类:
Skiplistpythonclass Skiplist: def __init__(self): self.max_level = 16 # 限制最大层数 self.head = Node(-1, self.max_level) # 头节点 self.level = 0 # 当前跳表的层数初始化部分
max_level:设置跳表支持的最大层数为 16,这里限制了跳表中最高的层数,防止无限制增加层级。head:创建一个哨兵节点(头节点),值设为-1。头节点拥有max_level + 1个指针(即 0 到 16 层),方便在所有层上统一处理边界问题。level:当前跳表实际使用的最高层,初始为 0。随着节点插入,可能会逐步增加。随机层数生成器:
random_levelpythondef random_level(self): level = 0 while random.random() < 0.5 and level < self.max_level: level += 1 return level
- 逻辑解释:
- 初始化
level为 0。- 使用
random.random()生成一个 [0, 1) 之间的随机浮点数,如果小于 0.5,就将level增加 1。- 同时保证生成的层数不超过
max_level。- 作用:随机生成节点的层数。通过 50% 的概率增加层数,使得大部分节点只存在于较低的层级,而少部分节点延伸到较高层级,从而达到平衡查找的目的,使平均时间复杂度保持在 (O(\log n))。
搜索方法:
searchpythondef search(self, target: int) -> bool: current = self.head for i in range(self.level, -1, -1): while current.next[i] and current.next[i].value < target: current = current.next[i] current = current.next[0] return current is not None and current.value == target
- 实现过程:
- 从最高层开始:从当前跳表的最高层
self.level开始向下遍历。- 在每一层内前进:在第
i层上,利用while循环不断沿着指针前进,直到遇到下一个节点的值不小于target为止。- 转到下一层:当当前层遍历完成后,下降到下一层继续查找。
- 在第0层验证:最后检查第 0 层的节点是否等于目标值
target。- 返回值:如果找到节点且值等于
target则返回True,否则返回False。插入方法:
addpythondef add(self, num: int) -> None: update = [None] * (self.max_level + 1) current = self.head for i in range(self.level, -1, -1): while current.next[i] and current.next[i].value < num: current = current.next[i] update[i] = current level = self.random_level() if level > self.level: for i in range(self.level + 1, level + 1): update[i] = self.head self.level = level new_node = Node(num, level) for i in range(level + 1): new_node.next[i] = update[i].next[i] update[i].next[i] = new_node
- 实现过程:
- 寻找插入位置:
- 定义一个
update数组,用于记录每一层中,待插入节点前一个节点的引用。- 从最高层开始,利用与
search类似的方式,找到每一层中最后一个小于num的节点,并记录在update[i]中。- 生成随机层数:
- 调用
random_level()方法,为新节点随机生成层数。- 调整跳表层数:
- 如果新节点的层数比当前跳表的最高层还高,则在
update数组中,将新层的前驱节点统一设为head,并更新self.level。- 插入节点:
- 创建新节点
new_node。- 对于新节点的每一层,将其指针连接到
update[i]的后继节点,同时将update[i]的后继指针指向new_node。- 关键点:
- 利用
update数组保存了插入路径,使得在每一层都能直接插入新节点,而不需要再次从头遍历。删除方法:
erasepythondef erase(self, num: int) -> bool: update = [None] * (self.max_level + 1) current = self.head for i in range(self.level, -1, -1): while current.next[i] and current.next[i].value < num: current = current.next[i] update[i] = current current = current.next[0] if current is None or current.value != num: return False for i in range(self.level + 1): if update[i].next[i] != current: break update[i].next[i] = current.next[i] while self.level > 0 and self.head.next[self.level] is None: self.level -= 1 return True
- 实现过程:
- 寻找待删除节点:
- 同样使用
update数组,遍历每一层查找目标num的前一个节点。- 通过
current = current.next[0]得到第 0 层中可能等于num的节点。- 判断节点是否存在:
- 如果
current为None或其value不等于num,则说明目标节点不存在,返回False。- 更新指针删除节点:
- 对于每一层,若
update[i].next[i]正好指向要删除的节点,则将该指针直接跳过待删除节点,指向current.next[i]。- 调整跳表的当前层数:
- 删除节点后,可能导致某一层中没有节点存在。如果最高层为空,则降低跳表的层数
self.level。- 返回值:如果成功删除,则返回
True,否则返回False。总结
跳表结构:利用多层链表,最底层保存所有元素,每一层作为加速索引。
随机性:通过
random_level确保节点层数随机分布,大部分节点在低层,高层节点较少,从而使查找、插入、删除操作平均时间复杂度为。 核心操作:
- 搜索:从高层开始逐步下降,直至精确查找目标值。
- 插入:先确定各层的插入位置,再根据随机层数调整结构。
- 删除:类似插入,先定位,再调整各层指针,同时更新跳表的当前层数。
这份代码实现展示了跳表的基本思想和操作逻辑,通过精心设计的层次结构,使得对有序数据的增删查操作变得高效且简洁。
除了问AI解读程序,这个可视化工具也很好用,https://pythontutor.com/