1203.项目管理
dfs, bfs, graphs, topological order, https://leetcode.cn/problems/sort-items-by-groups-respecting-dependencies/
有 n 个项目,每个项目或者不属于任何小组,或者属于 m 个小组之一。group[i] 表示第 i 个项目所属的小组,如果第 i 个项目不属于任何小组,则 group[i] 等于 -1。项目和小组都是从零开始编号的。可能存在小组不负责任何项目,即没有任何项目属于这个小组。
请你帮忙按要求安排这些项目的进度,并返回排序后的项目列表:
- 同一小组的项目,排序后在列表中彼此相邻。
- 项目之间存在一定的依赖关系,我们用一个列表
beforeItems来表示,其中beforeItems[i]表示在进行第i个项目前(位于第i个项目左侧)应该完成的所有项目。
如果存在多个解决方案,只需要返回其中任意一个即可。如果没有合适的解决方案,就请返回一个 空列表 。
示例 1:
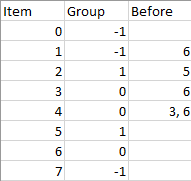
输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3,6],[],[],[]]
输出:[6,3,4,1,5,2,0,7]示例 2:
输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3],[],[4],[]]
输出:[]
解释:与示例 1 大致相同,但是在排序后的列表中,4 必须放在 6 的前面。提示:
1 <= m <= n <= 3 * 10^4group.length == beforeItems.length == n-1 <= group[i] <= m - 10 <= beforeItems[i].length <= n - 10 <= beforeItems[i][j] <= n - 1i != beforeItems[i][j]beforeItems[i]不含重复元素
98ms,击败72.50%
python
from collections import defaultdict, deque
from typing import List
class Solution:
def sortItems(self, n: int, m: int, group: List[int], beforeItems: List[List[int]]) -> List[int]:
# Step 1: Assign independent groups for items without a group (-1)
for i in range(n):
if group[i] == -1:
group[i] = m
m += 1 # Assign a new group index
# Step 2: Build dependency graphs (item graph + group graph)
item_graph = defaultdict(list) # Graph for item dependencies
group_graph = defaultdict(list) # Graph for group dependencies
item_indegree = [0] * n # Indegree for items
group_indegree = [0] * m # Indegree for groups
group_to_items = [[] for _ in range(m)] # Map group to its items
# Step 3: Fill graphs based on dependencies
for i in range(n):
group_to_items[group[i]].append(i) # Group mapping
for before in beforeItems[i]:
item_graph[before].append(i)
item_indegree[i] += 1
# If dependencies cross groups, update group graph
if group[before] != group[i]:
group_graph[group[before]].append(group[i])
group_indegree[group[i]] += 1
# Step 4: Perform topological sort on groups
def topological_sort(graph, indegree, nodes):
queue = deque([node for node in nodes if indegree[node] == 0])
order = []
while queue:
node = queue.popleft()
order.append(node)
for neighbor in graph[node]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
queue.append(neighbor)
return order if len(order) == len(nodes) else []
# Get valid group order
group_order = topological_sort(group_graph, group_indegree, range(m))
if not group_order:
return [] # Cycle detected in group dependencies
# Step 5: Perform topological sort on items
item_order = topological_sort(item_graph, item_indegree, range(n))
if not item_order:
return [] # Cycle detected in item dependencies
# Step 6: Arrange sorted items by group order
item_position = {item: idx for idx, item in enumerate(item_order)}
result = []
for g in group_order:
#result.extend(sorted(group_to_items[g], key=lambda x: item_position[x]))
result += sorted(group_to_items[g], key=lambda x: item_position[x])
return result
# Test cases
if __name__ == '__main__':
n = 8
m = 2
group = [-1, -1, 1, 0, 0, 1, 0, -1]
beforeItems = [[], [6], [5], [6], [3, 6], [], [], []]
print(Solution().sortItems(n, m, group, beforeItems)) # Output: [6, 3, 4, 1, 5, 2, 0, 7]优化点
一次性拓扑排序:
item_graph只进行 一次拓扑排序,避免了多次对子图进行额外计算。- 这样可以 大幅度减少拓扑排序的次数,优化时间复杂度。
使用
item_position进行排序:
- 由于
item_order是正确的拓扑排序,我们使用item_position[x]确保组内的相对顺序。预分配
group_to_items:
- 直接使用 列表 而不是
defaultdict(list),减少字典操作,提高访问速度。复杂度分析
- 构建图:O(n + e),其中
e是beforeItems的依赖关系数量- 拓扑排序:
- Group Sort: O(m + g)(
g是小组间依赖数)- Item Sort: O(n + e)
- 排序项目顺序:O(n log n)(对每个小组的项目进行排序)
总复杂度:O(n log n + e + g) ≈ O(n log n),在 大数据 下会有 明显的性能提升!
87ms,击败82.50%
python
from collections import defaultdict, deque
from typing import List
class Solution:
def sortItems(self, n: int, m: int, group: List[int], beforeItems: List[List[int]]) -> List[int]:
# Step 1: Assign independent groups for items without a group (-1)
for i in range(n):
if group[i] == -1:
group[i] = m
m += 1 # Assign a new group index
# Step 2: Build dependency graphs (item graph + group graph)
#item_graph = defaultdict(list) # Graph for item dependencies
item_graph = [[] for _ in range(n)]
#group_graph = defaultdict(list) # Graph for group dependencies
group_graph = [[] for _ in range(m)]
item_indegree = [0] * n # Indegree for items
group_indegree = [0] * m # Indegree for groups
group_to_items = [[] for _ in range(m)] # Map group to its items
# Step 3: Fill graphs based on dependencies
for i in range(n):
group_to_items[group[i]].append(i) # Group mapping
for before in beforeItems[i]:
item_graph[before].append(i)
item_indegree[i] += 1
# If dependencies cross groups, update group graph
if group[before] != group[i]:
group_graph[group[before]].append(group[i])
group_indegree[group[i]] += 1
# Step 4: Perform topological sort on groups
def topological_sort(graph, indegree, nodes):
queue = deque([node for node in nodes if indegree[node] == 0])
order = []
while queue:
node = queue.popleft()
order.append(node)
for neighbor in graph[node]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
queue.append(neighbor)
return order if len(order) == len(nodes) else []
# Get valid group order
group_order = topological_sort(group_graph, group_indegree, range(m))
if not group_order:
return [] # Cycle detected in group dependencies
# Step 5: Perform topological sort on items
item_order = topological_sort(item_graph, item_indegree, range(n))
if not item_order:
return [] # Cycle detected in item dependencies
# Step 6: Arrange sorted items by group order
item_position = {item: idx for idx, item in enumerate(item_order)}
result = []
for g in group_order:
#result.extend(sorted(group_to_items[g], key=lambda x: item_position[x]))
result += sorted(group_to_items[g], key=lambda x: item_position[x])
#result += [x for x in item_order if group[x] == g] # 直接遍历 item_order 来拼接。用这条语句,超时了。
return result
# Test cases
if __name__ == '__main__':
n = 8
m = 2
group = [-1, -1, 1, 0, 0, 1, 0, -1]
beforeItems = [[], [6], [5], [6], [3, 6], [], [], []]
print(Solution().sortItems(n, m, group, beforeItems)) # Output: [6, 3, 4, 1, 5, 2, 0, 7]用
list代替defaultdict(list)优化前:
from collections import defaultdict group_to_items = defaultdict(list)优化后:
group_to_items = [[] for _ in range(m)]为什么更快?
defaultdict(list)需要哈希查找,而list直接索引访问,省去了dict的哈希计算时间。- 这样可以 减少 Python 解释器的
dict操作开销。
extend()改为+=**优化前:
result.extend([...])优化后:
result += [...]为什么更快?
extend()其实是 Python 层面的循环,而+=会直接调用 C 实现的list.__iadd__(),更快。