T3327.判断 DFS 字符串是否是回文串
dfs, manacher, https://leetcode.cn/problems/check-if-dfs-strings-are-palindromes/
给你一棵 n 个节点的树,树的根节点为 0 ,n 个节点的编号为 0 到 n - 1 。这棵树用一个长度为 n 的数组 parent 表示,其中 parent[i] 是节点 i 的父节点。由于节点 0 是根节点,所以 parent[0] == -1 。
给你一个长度为 n 的字符串 s ,其中 s[i] 是节点 i 对应的字符。
一开始你有一个空字符串 dfsStr ,定义一个递归函数 dfs(int x) ,它的输入是节点 x ,并依次执行以下操作:
- 按照 节点编号升序 遍历
x的所有孩子节点y,并调用dfs(y)。 - 将 字符
s[x]添加到字符串dfsStr的末尾。
注意,所有递归函数 dfs 都共享全局变量 dfsStr 。
你需要求出一个长度为 n 的布尔数组 answer ,对于 0 到 n - 1 的每一个下标 i ,你需要执行以下操作:
- 清空字符串
dfsStr并调用dfs(i)。 - 如果结果字符串
dfsStr是一个 回文串 ,answer[i]为true,否则answer[i]为false。
请你返回字符串 answer 。
示例 1:
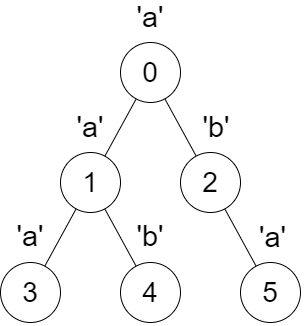
输入:parent = [-1,0,0,1,1,2], s = "aababa"
输出:[true,true,false,true,true,true]
解释:
- 调用
dfs(0),得到字符串dfsStr = "abaaba",是一个回文串。 - 调用
dfs(1),得到字符串dfsStr = "aba",是一个回文串。 - 调用
dfs(2),得到字符串dfsStr = "ab",不 是回文串。 - 调用
dfs(3),得到字符串dfsStr = "a",是一个回文串。 - 调用
dfs(4),得到字符串dfsStr = "b",是一个回文串。 - 调用
dfs(5),得到字符串dfsStr = "a",是一个回文串。
示例 2:
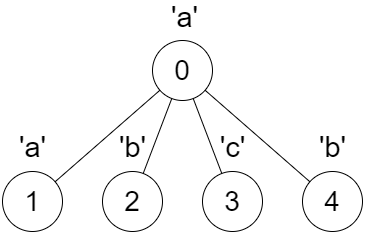
输入:parent = [-1,0,0,0,0], s = "aabcb"
输出:[true,true,true,true,true]
解释:
每一次调用 dfs(x) 都得到一个回文串。
提示:
n == parent.length == s.length1 <= n <= 10^5- 对于所有
i >= 1,都有0 <= parent[i] <= n - 1。 parent[0] == -1parent表示一棵合法的树。s只包含小写英文字母。
为了高效解决这个问题,我们需要处理两个核心点:
- 如何快速获取每个子树生成的 DFS 字符串:题目定义的 DFS 顺序是“先递归访问升序排列的孩子,再添加当前节点字符”。这本质上是带有子节点排序约束的后序遍历。在这种遍历下,任意节点
生成的字符串 dfsStr(i)恰好是全局后序遍历字符串的一个连续子串。 - 如何高效判断子串是否为回文串:由于节点数
,我们不能显式构建每个字符串,否则时间复杂度会退化到 。我们可以预先生成全局字符串,然后利用 Manacher 算法 或 字符串哈希 在 时间内判断任意子串是否为回文。
算法步骤:
- 构建并排序树结构:根据
parent数组建立邻接表,并对每个节点的孩子列表按编号升序排序。 - 生成后序遍历序列:使用迭代式 DFS(避免深度过大的树导致栈溢出)获取全局后序遍历得到的字符串
order。同时记录每个节点在 order中对应的起始索引start[i]和结束索引end[i]。 - Manacher 算法预处理:对字符串
order执行 Manacher 算法,计算以每个位置为中心的最大回文半径。 - 查询并得出结果:对于每个节点
,其对应的字符串长度为 len = end[i] - start[i] + 1,中心位置映射到 Manacher 数组中的位置。通过比较该中心的最大回文半径是否大于等于len,即可判断其是否为回文。
Python 代码实现:
python
from typing import List
class Solution:
def findAnswer(self, parent: List[int], s: str) -> List[bool]:
n = len(parent)
if n == 0:
return []
# 1. 构建邻接表并对孩子节点进行升序排序
adj = [[] for _ in range(n)]
for i in range(1, n):
adj[parent[i]].append(i)
for i in range(n):
if len(adj[i]) > 1:
adj[i].sort()
# 2. 迭代式后序遍历 (Post-order DFS)
# 记录全局遍历字符串 order 和每个子树对应的区间 [start, end]
order = [None] * n
start = [0] * n
end = [0] * n
curr_time = 0
# stack 存储 (节点, 状态); 状态 0: 准备访问孩子, 1: 孩子访问完毕,处理当前节点
stack = [(0, 0)]
while stack:
u, state = stack.pop()
if state == 0:
start[u] = curr_time
stack.append((u, 1))
# 栈是后进先出,为了升序访问孩子,需降序压入栈
children = adj[u]
for i in range(len(children) - 1, -1, -1):
stack.append((children[i], 0))
else:
# 记录字符并更新时间戳
order[curr_time] = s[u]
end[u] = curr_time
curr_time += 1
# 3. Manacher's Algorithm 预处理
# 构造填充字符串以处理偶数长度回文,例如 "aba" -> "#a#b#a#"
m_str = ['#'] * (2 * n + 1)
for i in range(n):
m_str[2 * i + 1] = order[i]
m = len(m_str)
p = [0] * m # p[i] 存储以 i 为中心的最大回文半径(在原串中的长度)
center = 0
right_boundary = 0
for i in range(m):
if i < right_boundary:
p[i] = min(right_boundary - i, p[2 * center - i])
# 尝试中心扩展
l_ptr, r_ptr = i - (p[i] + 1), i + (p[i] + 1)
while l_ptr >= 0 and r_ptr < m and m_str[l_ptr] == m_str[r_ptr]:
p[i] += 1
l_ptr -= 1
r_ptr += 1
# 更新右边界和中心
if i + p[i] > right_boundary:
center, right_boundary = i, i + p[i]
# 4. 根据 Manacher 结果判断每个节点的区间是否为回文
ans = [False] * n
for i in range(n):
l_idx, r_idx = start[i], end[i]
length = r_idx - l_idx + 1
# 子串 order[l_idx...r_idx] 在 m_str 中的中心索引为 l_idx + r_idx + 1
mid_in_m = l_idx + r_idx + 1
if p[mid_in_m] >= length:
ans[i] = True
return ans复杂度分析:
- 时间复杂度:
。构建树和遍历是 ,对所有孩子节点排序的总代价在最坏情况下(星型树)为 。Manacher 算法是 。最终查询每个节点是 。 - 空间复杂度:
。用于存储邻接表、Manacher 半径数组 p以及辅助字符串m_str。