T01037: A decorative fence
dp, http://cs101.openjudge.cn/practice/01037/
Richard just finished building his new house. Now the only thing the house misses is a cute little wooden fence. He had no idea how to make a wooden fence, so he decided to order one. Somehow he got his hands on the ACME Fence Catalogue 2002, the ultimate resource on cute little wooden fences. After reading its preface he already knew, what makes a little wooden fence cute. A wooden fence consists of N wooden planks, placed vertically in a row next to each other. A fence looks cute if and only if the following conditions are met: The planks have different lengths, namely 1, 2, . . . , N plank length units. Each plank with two neighbors is either larger than each of its neighbors or smaller than each of them. (Note that this makes the top of the fence alternately rise and fall.) It follows, that we may uniquely describe each cute fence with N planks as a permutation a1, . . . , aN of the numbers 1, . . . ,N such that (any i; 1 < i < N) (ai − ai−1)*(ai − ai+1) > 0 and vice versa, each such permutation describes a cute fence. It is obvious, that there are many dierent cute wooden fences made of N planks. To bring some order into their catalogue, the sales manager of ACME decided to order them in the following way: Fence A (represented by the permutation a1, . . . , aN) is in the catalogue before fence B (represented by b1, . . . , bN) if and only if there exists such i, that (any j < i) aj = bj and (ai < bi). (Also to decide, which of the two fences is earlier in the catalogue, take their corresponding permutations, find the first place on which they differ and compare the values on this place.) All the cute fences with N planks are numbered (starting from 1) in the order they appear in the catalogue. This number is called their catalogue number. 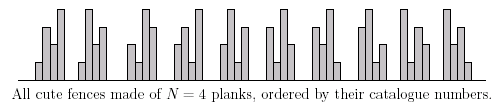 After carefully examining all the cute little wooden fences, Richard decided to order some of them. For each of them he noted the number of its planks and its catalogue number. Later, as he met his friends, he wanted to show them the fences he ordered, but he lost the catalogue somewhere. The only thing he has got are his notes. Please help him find out, how will his fences look like.
After carefully examining all the cute little wooden fences, Richard decided to order some of them. For each of them he noted the number of its planks and its catalogue number. Later, as he met his friends, he wanted to show them the fences he ordered, but he lost the catalogue somewhere. The only thing he has got are his notes. Please help him find out, how will his fences look like.
输入
The first line of the input file contains the number K (1 <= K <= 100) of input data sets. K lines follow, each of them describes one input data set. Each of the following K lines contains two integers N and C (1 <= N <= 20), separated by a space. N is the number of planks in the fence, C is the catalogue number of the fence. You may assume, that the total number of cute little wooden fences with 20 planks fits into a 64-bit signed integer variable (long long in C/C++, int64 in FreePascal). You may also assume that the input is correct, in particular that C is at least 1 and it doesn抰 exceed the number of cute fences with N planks.
输出
For each input data set output one line, describing the C-th fence with N planks in the catalogue. More precisely, if the fence is described by the permutation a1, . . . , aN, then the corresponding line of the output file should contain the numbers ai (in the correct order), separated by single spaces.
样例输入
2
2 1
3 3样例输出
1 2
2 3 1来源
CEOI 2002
详细解释,可以参考《算法基础与在线实践》.pdf。
# http://cs101.openjudge.cn/practice/01037/
#
# https://blog.csdn.net/u014236804/article/details/38373729
# POJ1037 A decorative fence by Guo Wei
UP = 0
DOWN = 1
MAXN = 25
arr = lambda m,n,l : [ [ [0 for k in range(l)] for j in range(n)] for i in range(m) ]
#m = arr(2,3,4)
# C[i][k][DOWN] 是S(i)中以第k短的木棒打头的DOWN方案数,C[i][k][UP] 是S(i)中以第k短的木棒打头的UP方案数,第k短指i根中第k短
C = arr(MAXN, MAXN, 2)
def Init(n: int):
C[1][1][UP] = C[1][1][DOWN] = 1
for i in range(2, n+1):
for k in range(1, i+1): # 枚举第一根木棒的长度
for M in range(k, i): # 枚举第二根木棒的长度
C[i][k][UP] += C[i-1][M][DOWN]
for N in range(1, k): # 枚举第二根木棒的长度
C[i][k][DOWN] += C[i-1][N][UP]
# 总方案数是 Sum{ C[n][k][DOWN] + C[n][k][UP] } k = 1.. n;
def Print(n: int, cc: int):
skipped = 0 #已经跳过的方案数
seq = [0]*MAXN #最终要输出的答案
used = [False]*MAXN #木棒是否用过
for i in range(1, n+1): # 依次确定每一个位置i的木棒序号
oldVal = skipped
k = 0
No = 0 # k是剩下的木棒里的第No短的,No从1开始算
for k in range(1, n+1): # 枚举位置i的木棒 ,其长度为k
oldVal = skipped
if used[k]==False:
No += 1 # k是剩下的木棒里的第No短的
if i == 1:
skipped += C[n][No][UP] + C[n][No][DOWN]
else:
if k > seq[i-1] and ( i <=2 or seq[i-2]>seq[i-1]): #合法放置
skipped += C[n-i+1][No][DOWN]
elif k < seq[i-1] and (i<=2 or seq[i-2]<seq[i-1]): #合法放置
skipped += C[n-i+1][No][UP]
if skipped >= cc:
break
used[k] = True
seq[i] = k
skipped = oldVal
print(' '.join(map(str, seq[1:n+1])))
'''
for i in range(1, n+1):
print("{}".format(seq[i]), end=' ')
print()
'''
Init(20);
for _ in range(int(input())):
n, c = map(int, input().split())
Print(n,c)【陈子良 25物理学院】此题本质上就是提取数字1~N的各种排列中高低交替的一部分,把这些排列按字典序的顺序排开,然后问第C个排列是什么。
这题让我想到了康托展开。康托展开(Cantor Expansion)是一种将排列映射到唯一整数的方法。比如下面的代码输出某一个排列后方的第k个排列:
n,k=map(int,input().split())
factorial=[1]
for i in range(1,n+1):
factorial.append(factorial[-1]*i)
p1=list(map(int,input().split()))
p0=list(range(1,n+1))
l=n-1
a=0
for p in p1:
a+=p0.index(p)*factorial[l]
p0.remove(p)
l-=1
b=(a+k)%(factorial[n])
p2=[]
p0=list(range(1,n+1))
l=n-1
while p0:
p2.append(p0.pop(b//factorial[l]))
b%=factorial[l]
l-=1
print(*p2)用一个例子理解康托展开的基本思路:比如我们要确定排列[3,5,2,4,1]的字典序,首先我们看排列第一个位置,如果它是1的话,后面四个数的排列就有4!种;如果它是2的话,后面四个数的排列也为4!种。因此排列[3,5,2,4,1]的字典序就是2*4!加上[5,2,4,1]的字典序。当判断[5,2,4,1]的字典序时,比5小的数字只有三个,类似之前的讨论,它的字典序就是3*3!加上[2,4,1]的字典序。以此类推,便可得到原排列的字典序为2*4!+3*3!+1*2!+1*1!=69。
这种算法最鲜明的特点是它并不关心排列中实际数字的大小,而只关心它们间的相对大小。比如在判断第二个数字5时,无论后面的数字是[1,2,3]、[1,2,4]还是其他数字,都不影响结果,只要5是排列中第四大的数字,这一位对字典序的贡献都是3*3!。
康托展开的逆过程也是类似的。比如我们要找第69个排列。我们维护一个顺序排列[1,2,3,4,5]。首先,如果排列的首位是1,就有4!=24种排列,24<69,说明首位数字要往后推;如果排列的首位是2,那么在首位是1的基础上再加上4!=24,字典序变为48,48<69,再往后推;如果首位是3,有72>69种可能。那么排列的首位就是3了,而后面的数字要从[1,2,4,5]中找,找到第69-48=21个排列。对于排列的第二位,有3*3!<21<4*3!,因此第二位是现存数中第四大的,也就是5,剩下的三位从[1,2,4]中找,找第21-3*3!=3个排列。以此类推,就得到排列是[3,5,2,1,4]。
回到本题,其实本题与康托展开的过程非常相似,只是当不同数字放在排列首位时,存在的排列数量不同。在传统的康托展开中,无论首位是1,2还是3,后面四个数的排列数都是4!,但现在因为有了“高低交替”的要求,首位是1、2或3时后面四个数的排列数就有可能不同。
假设我们通过某种方式知道了将各个数放在首位时的排列数,现在判断第C个排列是什么。我们维护一个顺序排列[1,2,3,4,5]。首先假设首位是1,我们判断C与dfs('5个数的排列,1放在首位的“高低交替”的排列数')的大小,如果前者较大,就先减掉后者,将首位变为2,判断此时的C与dfs('5个数的排列,2放在首位的“高低交替”的排列数'),大小。直到首位为a1时字典序大于C,那么首位就是a1,在顺序排列中去掉a1,找四个数的排列中字典序为此时的C的那个排列。
如何计算上面所谓dfs('n个数的排列,a放在首位的“高低交替”的排列数')呢?我们可以沿用康托展开中的思想。我们不关心现存排列中数的实际大小,只关心它们的相对大小。假设在这n个数中比a大的数有b个,比a小的数有s个。显然b+s=n-1。我们寻找dfs('n个数的排列,a放在首位,上升趋势的排列')时,可以从比a大的b个数中任选一个a1放在a的后面,待求值就是它们对应的排列数之和。这些排列应满足有n-1个数,a1放在首位,下降趋势。即
dfs('n个数的排列,a放在首位,上升趋势的排列')
=sum([dfs('n-1个数的排列,a1放在首位,下降趋势的排列') for a1 in ['比a大的数']])对于这b个数中第i大的数ai,容易知道,如果将它放在a的后方,那么ai后面的数中有b-i个数比它大,s+i-1个数比它小。当n==1时,就可以返回1。这样我们就找到了一个类似的子结构,可以进行递归。
现在我们用严谨的语言描述上述过程。我们用d表示当前排列的趋势,d==1表示上升,d==-1表示下降。设dfs(n,d,b,s)表示n个数的排列,趋势为d,将a放在排列首位时的排列数,其中a后面有b个数比a大,有s个数比a小。之前说过我们不关心数字的实际大小,因此参量a可以隐藏。运用之前的公式,我们得到dfs函数的递归公式如下:
def dfs(n,d,b,s):
if n==1:
return 1
if d==1:
return sum([dfs(n-1,-d,b-i,s+i-1) for i in range(1,b+1)])
elif d==-1:
return sum([dfs(n-1,-d,b+i-1,s-i) for i in range(1,s+1)])可以利用记忆化搜索functools.lru_cache加速求解过程。
为了判断字典序为C的排列p是什么,我们维护一个顺序排列p0=list(range(1,n+1)),不断尝试排列的首位元素。用C1表示当前检查到的排列的字典序,初始C1=0。如果当前排列的首位是顺序列表p0中第i个元素(i从0开始),那么它就有dfs(n,d,n-i-1,i)种可能,字典序是C1+dfs(n,d,n-i-1,i)。如果C1+dfs(n,d,n-i-1,i)<C,那么就将首位元素加一,C1+=dfs(n,d,n-i-1,i);如果C1+dfs(n,d,n-i-1,i)>=C,那么当前首位就是第i个元素了,将该元素从顺序列表p0中弹出,加入目标列表p中。如此类推直到p0为空。
对于整个排列的第一个元素需要特判,因为第一个位置既可能是上升趋势,也可能是下降趋势。后面的元素趋势一定是与上一位相反的。
【陈子良 25物理学院】这题让我联想到了康托展开,并利用相似的思路,结合记忆化搜索完成了这题。
from functools import lru_cache
for _ in range(int(input())):
N,C=map(int,input().split())
@lru_cache(maxsize=None)
def dfs(n,d,b,s):
if n==1:
return 1
if d==1:
return sum([dfs(n-1,-d,b-i,s+i-1) for i in range(1,b+1)])
elif d==-1:
return sum([dfs(n-1,-d,b+i-1,s-i) for i in range(1,s+1)])
p=[]
p0=list(range(1,N+1))
C1=0
for i in range(N):
if C1+dfs(N,-1,N-i-1,i)>=C:
p.append(p0.pop(i))
d0=-1
C-=C1
break
C1+=dfs(N,-1,N-i-1,i)
if C1+dfs(N,1,N-i-1,i)>=C:
p.append(p0.pop(i))
d0=1
C-=C1
break
C1+=dfs(N,1,N-i-1,i)
d=-d0
n=N-1
while p0:
C1=0
for i in range(n):
if d*p0[i]<d*p[-1]:
if C1+dfs(n,d,n-i-1,i)>=C:
p.append(p0.pop(i))
d=-d
n-=1
C-=C1
break
C1+=dfs(n,d,n-i-1,i)
print(*p)