25566: CPU 调度
http://cs101.openjudge.cn/practice/25566/
进程(Process)是运行中的程序。你平时使用计算机时打开的每一个不同的窗口,都对应着一个进程。一个进程通常需要进行两类操作:读写数据和计算。前者需要占用内存或硬盘中的某个文件,而后者需要独占所有进程共享的 CPU 资源。CPU 在每个时间周期内可以选择一个进程为其执行计算操作,这被称为 CPU 调度。假设现在有一组进程,每个进程 i 需要先累计占用 compute[i] 个 CPU 周期(不一定连续)进行计算,计算完成后需要 write[i] 个时间周期将结果写文件,随后进程结束。所有进程写的文件均不同,即写的过程可以同步进行。请你计算如何调度 CPU 能够使所有进程都结束的时间最早?
样例解释
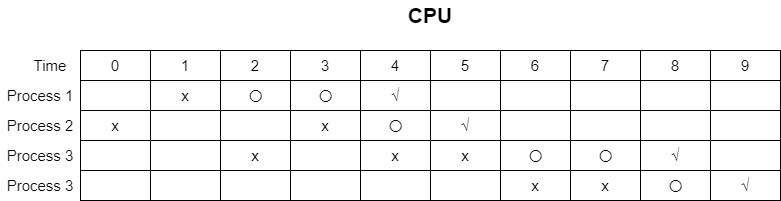
样例 1 和样例 2 的一种最优调度如下图所示,其中 x 代表占用 CPU 进行计算,〇 代表写文件,√ 代表该时刻进程结束。注意最优调度不一定唯一且例子所举的方法不一定与正确算法相关。
样例 1:

样例 2:
输入
第一行是一个正整数 n (1 <= n <= 200),表示进程的个数。
接下来 n 行,每行为空格分隔的 2 个正整数 compute[i] 和 write[i] ,表示每个进程 i 需要的 CPU 计算时间和写文件时间。
输出
一个正整数,表示所有进程完结的最早时间。假设时间从 0 开始。
样例输入
Sample Input1:
3
1 2
4 3
3 1
Sample Output1:
9样例输出
Sample Input1:
4
1 2
2 1
3 2
2 1
Sample Output2:
9提示
tags: greedy
来源: 2022fall-cs101, zyn
可以考虑有一个进程的读写数据实际特别长,那自然是它越早开始越好。而且它读写的时候,其他进程还可以并行计算。
为什么只需要按照写文件时间排序? 计算时间 (compute[i]) 是占用 CPU 的独占时间,调度顺序只会影响当前的 CPU 执行时间。 写文件时间 (write[i]) 可以与其他任务的计算时间重叠,因此 尽早开始写文件时间更长的任务,能最大程度地减少所有进程的完成时间。 因此,贪心策略的核心就是:按照写文件时间从大到小排序。
def earliest_completion_time():
n = int(input()) # 输入进程数
tasks = [] # 存储每个进程的 (compute, write)
for _ in range(n):
compute, write = map(int, input().split())
tasks.append((compute, write))
# 按 write 从大到小排序,如果相等则按 compute 从大到小排序
tasks.sort(key=lambda x: -x[1])
current_time = 0 # 当前的 CPU 时间
total_time = 0 # 所有进程的最早完成时间
for compute, write in tasks:
current_time += compute # 执行计算任务
total_time = max(total_time, current_time + write) # 计算完成后写文件,并更新最早完成时间
print(total_time)
earliest_completion_time()Greedy不容易一下想到正确策略,但是感觉还摸的着,可以尝试。
写可以并行,优先选择写文件时间较长的进程,以减少总的等待时间。计算不能并行,ans1 += l[i][0] 时间较短的进程应该尽早执行,以便尽快释放CPU资源。按照写文件时间(x[1])降序排列,如果写文件时间相同,则按照计算时间(x[0])升序排列。l.sort(key=lambda x: (-x[1], x[0]))
n = int(input())
l = []
for _ in range(n):
l.append(list(map(int, input().split())))
l.sort(key=lambda x: (-x[1], x[0]))
ans1 = ans2 = 0
for i in range(n):
ans1 += l[i][0]
ans2 = max(ans2, ans1+l[i][1])
print(ans2)