T30102: 完美交易窗口
monotonic stack, binary search, DSU, segment tree, http://cs101.openjudge.cn/practice/T30102/
作为一名量化交易员,你正在分析一只股票连续 N 秒内的价格数据,记录为一个数组 h = [h1, h2, ..., hN]。
根据你的三十年量化经验,你定义了一种“完美交易窗口”,并且想找出这组数据中最长的完美交易窗口有多少秒。具体地,“完美交易窗口” 是一个从第 i 秒到第 j 秒的连续时间段 [i...j],且必须满足以下所有条件:
- 完美买入: 必须在第
i秒买入,且h[i]必须是[i...j]这整个时间窗口内的最低价格。 - 完美卖出:必须在第
j秒卖出,且h[j]必须是[i...j]这整个时间窗口内的最高价格。 - 盈利交易:卖出价
h[j]必须严格大于买入价h[i](即h[j] > h[i])。 - 严格完美:在持有期间(即第
k秒,i < k < j),股价既不能等于你的买入价h[i],也不能等于你的卖出价h[j]。
输入
第一行包含一个整数 N (2 <= N <= 1,000,000),代表数据的持续时间(以秒为单位)。 接下来 N 行,每行包含一个整数 h_i (1 <= hi < 2^31),代表第 i 秒的股票价格。
输出
一行,包含一个整数,表示最长的“完美交易窗口”有多少秒。
样例输入
10
3
1
2
5
4
6
1
2
4
3样例输出
5提示
tag: monotonic stack, binary search
来源
2025 TA-lxy
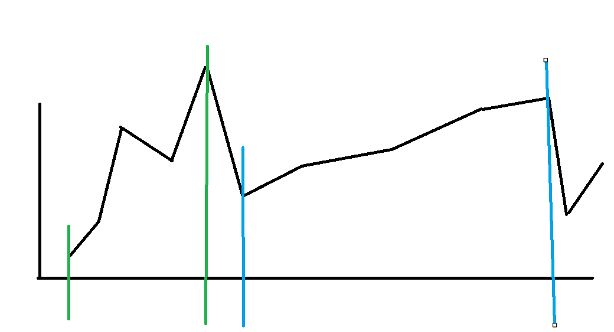
【李明阳 生科】思路:很多人都希望找价格尽可能低的地方买入,试试能向右延伸多远,如果出现比当前的购入点还小的值,就进行重置。但这种思路有一个“最大值屏蔽的问题”。比如拿到的是这样一个走势图,按照上面的方式,一味地选择尽可能小的位置买入,你将会获得绿色区间。然而,在最高点后面,还存在着更长的蓝色区间,尽管那个买入点的价格低得没有那么显著。所以,简单的单次遍历是不行的。为了更为全面地涵盖各种情况,我们需要新的思路。
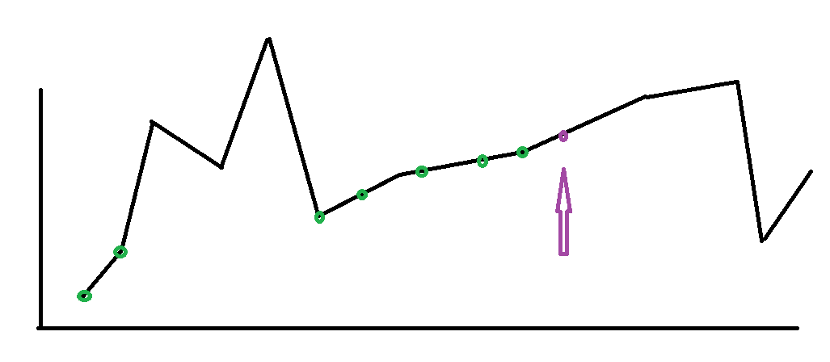
上面的问题在于,当我们固定左端点并左往右遍历时,右面没遍历到的地方还有什么我们是不知道的,当然也就不能严谨地变换左端点,这也是前面出错的原因。但我们如果把遍历到的每个点作为右端点,去考察以它作为右端点最多可以向左延伸多少,由于前面的情况已经清楚了,就可以得到正确的结论。
“最多可以向左延伸多少”这件事情,我们可以分两步来确定。首先,为了让现在的点是所选区间中的最大值,我们应该向左寻找第一个大于等于现在价位的点,这就是我们可能向左延伸的最远位置了。“第一个大于等于现在价位”可以用单调栈快速维护和查找。
下一步是确定在哪里买入。一个合法的买入点,它后面不可以出现比买入价格小的时刻,这些买入点本身的价位应当是递增的。下图展示了以紫色点作为右端点时可能的买入点位置。在右端点从左向右遍历的过程中,我们需要删除所有比当前价位高的时间点,因为这些不是合法的买入点;或者说,“最近的比现在价位低的点”就是最近的合法买入点。这种特征同样应该用单调栈维护。
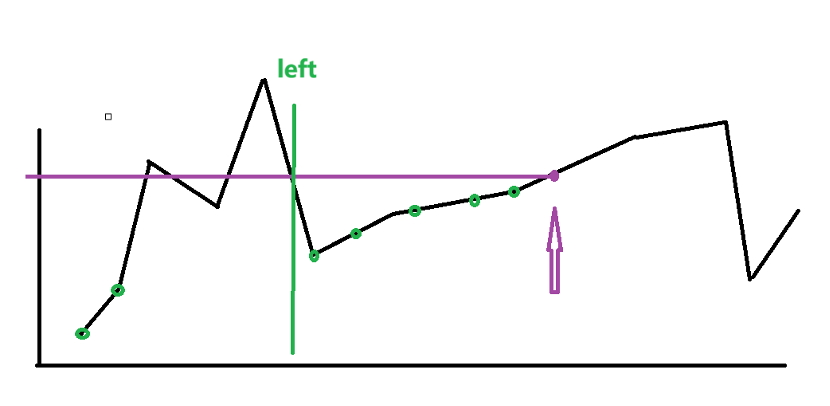
然后就是怎么确定最长区间的事情了。首先,我们找到最近的比现在价格高的位置left,左边界不能超出这里;否则,当前价格就不是最大值了。然后寻找left右边第一个合法的买入点,这件事可以借助bisect查询。总之,现在我们解决了这个问题。
代码
import sys
import bisect
input = sys.stdin.readline
def solve():
n = int(input())
prices = []
for i in range(n):
prices.append(int(input()))
ans = 0
i_stack = [] # 单调递增,用于确定每个点向左延伸的边界
b_stack = [] # 记录低点,确定买入
for i in range(n):
p = prices[i]
while i_stack and prices[i_stack[-1]] < p:
i_stack.pop()
if i_stack:
left = i_stack[-1]
else:
left = -1
while b_stack and prices[b_stack[-1]] >= p:
b_stack.pop()
if b_stack:
idx = bisect.bisect_left(b_stack, left)
if idx < len(b_stack):
buy = b_stack[idx]
ans = max(ans, i - buy + 1)
i_stack.append(i)
b_stack.append(i)
print(ans)
if __name__ == '__main__':
solve()思路:单调栈 + 二分查找
- 窗口右端点
为中心:我们遍历每一秒的价格作为卖出点(窗口右端点)。 - 最大值边界限制:使用单调递减栈
max_stk维护左侧第一个大于等于当前价格的位置。这个位置记为 left_barrier。为了满足是区间 的唯一最大值,买入点 必须满足 。 - 买入候选集:使用严格单调递增栈
buy_stk维护可能的买入点。- 当遇到价格
时,若栈顶价格 ,说明这些旧的买入点不再满足“ 是唯一最小值”或“严格完美”(中间不能等于买入价)的条件,直接弹出。 - 此时
buy_stk中留下的下标对应的价格都严格小于。
- 当遇到价格
- 二分查找最优解:由于
buy_stk中的下标是天然递增的,我们不再用遍历,而是用 的二分查找在栈中找到第一个大于 left_barrier的下标。这就是当前能构成的最长完美窗口的左端点。
Python 优化实现
import sys
from bisect import bisect_right
def solve():
# 使用 sys.stdin.read().split() 处理百万级数据最快
input_data = sys.stdin.read().split()
if not input_data:
return
n = int(input_data[0])
h = list(map(int, input_data[1:]))
# max_stk: 维护左侧第一个 >= h[j] 的位置
max_stk = []
# buy_stk: 存储所有可能的买入点 i 的下标(价格严格递增)
buy_stk = []
# 性能优化:缓存方法
m_pop = max_stk.pop
m_append = max_stk.append
b_pop = buy_stk.pop
b_append = buy_stk.append
res = 0
for j in range(n):
cur_p = h[j]
# 逻辑 1:寻找左侧第一个阻碍 h[j] 成为最大值的“大数”
while max_stk and h[max_stk[-1]] < cur_p:
m_pop()
# left_barrier 之前的下标都不能作为买入点 i
left_barrier = max_stk[-1] if max_stk else -1
# 逻辑 2:维护买入点候选集
# 如果当前卖出价 <= 某个买入价,该买入点失效(违反严格完美或盈利条件)
while buy_stk and h[buy_stk[-1]] >= cur_p:
b_pop()
# 逻辑 3:在候选买入点中,通过二分查找躲开左侧的“阻碍大数”
if buy_stk:
# 找到 buy_stk 中第一个大于 left_barrier 的下标位置
idx = bisect_right(buy_stk, left_barrier)
if idx < len(buy_stk):
best_i = buy_stk[idx]
# 计算当前完美窗口长度
res = max(res, j - best_i + 1)
# 将当前下标入栈
m_append(j)
b_append(j)
print(res)
if __name__ == "__main__":
solve()这是一个非常核心的逻辑问题。
max_stk(最大值边界栈)之所以是单调递减的,是由“寻找左侧第一个大于等于当前值”的需求决定的。我们可以从“谁有资格成为未来的障碍物”这个角度来理解:
1. 我们的目标是什么?
对于当前的卖出价
,我们需要找到它左侧第一个 的位置(记为 left_barrier)。
- 一旦找到这个位置,我们就知道:买入点
必须在 left_barrier的右边(即),否则 就不是区间内唯一的最高价了。 2. 为什么是“递减”的?(生存竞争逻辑)
假设我们从左往右扫描,手中维护着一个存储下标的栈。
当一个新的价格
准备入栈时,它会看一眼当前的栈顶价格 :
情况 A:
比栈顶 小。
- 此时
依然有存在的意义。因为对于未来的某个价格来说, 可能是它的第一个左侧大值,而 不是。 - 我们将
压入栈顶。现在的栈依然是递减的(比如: [100, 80, 50, j:30])。情况 B:
比栈顶 大。
- 这时候关键点来了:对于
之后的任何价格 来说, 已经永远失去了作为“第一个 障碍物”的资格。 - 为什么?因为
就在 的右边,且 。 - 如果未来某个
想要找左边第一个 它的数:
- 如果
,那么它在碰到 之前,必然先碰到比 更大、更近的 。 - 如果
, 显然也不是它要找的。 - 结论:
被 彻底“遮挡”了。它没用了,我们要把它弹出(pop)。 3. 结果:单调递减
由于我们会不断弹出栈中所有比
小的值,直到碰到一个 的值或者栈空为止:
- 留在栈里的元素,其对应的价格必然是从底到顶逐渐减小的。
- 栈顶永远是离当前
最近的、且价格比它大的那个数。 4. 形象的比喻:排队看日落
想象一排人从左往右站着(下标),每个人代表一个高度(价格)。
你站在位置
,向左看。你想知道谁是离你最近的、个子比你高(或一样高)的人。
- 如果前面有一个矮个子(
),他完全被你挡住了。后面的人向左看时,只会看到你,而看不到他。所以他从“视野名单”(栈)中消失。 - 当你把前面所有比你矮的人都踢出名单后,剩下的名单里:
- 最靠近你的那个人就是你的
left_barrier。- 整个名单从远到近,个子一定是越来越矮的(因为高个子会挡住后面的矮个子)。
总结
- 栈内元素(下标):单调递增(因为是按顺序入栈的)。
- 对应价格
:单调递减(因为价格大的会把左边价格小的“废掉”)。 - 作用:为了在
时间内定位 左侧的“天花板”,从而锁定完美窗口左端点 的活动范围。
为了在 Python 中高效地解决这个问题,我们需要在时间复杂度为
解题思路
窗口定义解析:
[i...j]是完美窗口,意味着是唯一最小值, 是唯一最大值。 - 严格完美条件
意味着在 范围内的所有股价必须严格大于买入价且严格小于卖出价。 - 通过单调栈,我们可以预处理:
:在 右侧第一个 的价格索引。如果不存在,设为 。 :在 左侧第一个 的价格索引。如果不存在,设为 。
- 判定条件:一个窗口
为完美交易窗口,当且仅当: (保证 是从 到 的最大值且唯一)。 (保证 是从 到 的最小值且唯一)。 。
算法设计:
- 我们需要找到满足
的最大 。 - 这是一个区间查询问题:对于每个
,我们需要在范围 中找到一个最小的 ,使得 。 - 我们可以利用并查集 (DSU) 来动态维护“活跃”的索引。一个索引
是活跃的,如果它满足 。随着 的增加,不满足条件的 会被“禁用”。并查集可以帮助我们快速跳过被禁用的索引,找到指定范围内的第一个活跃索引。
- 我们需要找到满足
Python 代码实现
import sys
from array import array
def solve():
# 使用生成器读取输入,节省内存
def get_input():
for line in sys.stdin:
for word in line.split():
yield word
input_gen = get_input()
try:
first_val = next(input_gen)
except StopIteration:
return
N = int(first_val)
if N < 2:
print(0)
return
# 使用 array.array 节省内存空间
h = array('I', map(int, input_gen))
# 1. 预处理 R_le: 右侧第一个比当前值小或相等的元素索引
R_le = array('i', [N] * N)
stack = []
stack_pop = stack.pop
stack_append = stack.append
for i in range(N):
hi = h[i]
while stack and hi <= h[stack[-1]]:
R_le[stack_pop()] = i
stack_append(i)
# 2. 预处理 L_ge: 左侧第一个比当前值大或相等的元素索引
L_ge = array('i', [-1] * N)
stack = []
stack_pop = stack.pop
stack_append = stack.append
for j in range(N):
hj = h[j]
while stack and hj > h[stack[-1]]:
stack_pop()
if stack:
L_ge[j] = stack[-1]
stack_append(j)
del h # 释放内存
# 3. 将索引按 R_le 值分组,用于在 j 推进时“禁用”不再满足 R_le[i] > j 的 i
head = array('i', [-1] * (N + 1))
nxt = array('i', [-1] * N)
for i in range(N):
r = R_le[i]
if r <= N:
nxt[i] = head[r]
head[r] = i
del R_le # 释放内存
# 4. 并查集维护活跃索引
# parent[i] 指向索引 i 或其后第一个活跃(R_le[i] > j)的索引
parent = array('i', range(N + 1))
p_arr = parent
max_len = 0
l_ge_arr = L_ge
h_arr = head
n_arr = nxt
for j in range(N):
# 禁用所有 R_le[i] == j 的 i
idx = h_arr[j]
while idx != -1:
# 执行并查集查找下一个活跃位置
r_target = idx + 1
while p_arr[r_target] != r_target:
r_target = p_arr[r_target]
p_arr[idx] = r_target
idx = n_arr[idx]
# 查询 (L_ge[j], j) 范围内的最小活跃索引 i
start_node = l_ge_arr[j] + 1
root = start_node
# 路径压缩查找
while p_arr[root] != root:
root = p_arr[root]
# 手动路径压缩以提速
curr = start_node
while p_arr[curr] != root:
temp = p_arr[curr]
p_arr[curr] = root
curr = temp
# 如果找到的最小活跃索引 i < j,则 [i, j] 是完美窗口
if root < j:
length = j - root + 1
if length > max_len:
max_len = length
sys.stdout.write(str(max_len) + '\n')
if __name__ == '__main__':
solve()关键点解释:
- 单调栈预处理:通过两次单调栈扫描,我们在
时间内确定了每个位置作为买入点或卖出点的边界约束。 - 并查集动态筛选:由于我们按顺序处理卖出时间
,当 增加时,某些买入点 因为其右侧出现了更低的价格(即 )而失效。并查集让我们能以几乎 的摊还时间找到左侧边界 之后第一个仍然有效的 。 - 内存管理:使用
array.array替代 Python 原生列表,并及时del不再需要的数组,确保程序在 128MB 限制内运行。 - 性能优化:通过内联并查集逻辑(减少函数调用)和局部变量引用,最大化 Python 在百万级数据下的执行速度。
【张颢缤 物院】想到一种方法:首先维护一个递增栈nums[mx_idx[i]]>=nums[mx]时更新为mx_idx[i]即可。此
import sys
def main():
data = sys.stdin.read().split()
n = int(data[0])
nums = list(map(int, data[1:n+1]))
nums.append(-1)
l = []
ans = 0
for r in range(n + 1):
v = nums[r]
mx = r
while l and nums[l[-1][0]] >= v:
tmp = l.pop()
if mx != r:
ans = max(ans, mx - tmp[0] + 1)
if nums[tmp[1]] >= nums[mx]:
mx = tmp[1]
l.append([r, mx])
print(ans)
main()基于线调栈和线段树(Segment Tree)的思路,处理
为了通过 128MB 的限制并尽可能在 1000ms 内运行,我们采用迭代式线段树(Z-tree),并使用 array.array 这种紧凑的内存结构来存储数据。
解题思路
- 线段树选型:使用迭代(非递归)线段树。数组大小设为
,以便利用位运算快速定位。 - 数据打包:线段树每个节点存储一个 64 位整数,将“价格”存入高位,将“位置(索引)的反转”存入低位。这样通过一个
max操作,就能同时选出最高价格以及在该价格相同时最靠左的位置。 - 单调栈逻辑:
- 维护一个递增单调栈,确定每个价格
作为“唯一最小值”的统治区间 。 - 当
的统治结束时(遇到一个更小或相等的 ),在线段树中查询 范围内的最高价位置 。 - 如果
,则更新最大长度 。
- 维护一个递增单调栈,确定每个价格
- 内存优化:使用
array.array('Q')存储线段树(每个元素 8 字节),使用array.array('I')存储原始价格(每个元素 4 字节),避免使用 Python 原生列表存储百万级整数对象。
Python 代码实现
import sys
from array import array
def solve():
# 1. 快速读取输入并限制内存消耗
# read().split() 对于百万级数据是最高效的读取方式,但会产生字符串列表
try:
raw_input = sys.stdin.buffer.read().split()
except EOFError:
return
if not raw_input:
return
n = int(raw_input[0])
# 使用 array.array ('I' 为无符号32位整型) 极其节省内存
h = array('I', map(int, raw_input[1:]))
del raw_input # 及时释放原始字符串列表以节省内存
# 2. 线段树初始化 (迭代式)
# size 必须是 2 的幂
size = 1 << (n - 1).bit_length()
# tree 存储打包数据: (价格 << 21) | (size - 索引)
# 21位足够存储 1,000,000 索引,高位存储价格确保最大值优先
# 'Q' 为无符号 64 位整型
tree = array('Q', [0]) * (2 * size)
# 填充叶子节点
for i in range(n):
tree[size + i] = (h[i] << 21) | (size - i)
# 构建线段树 (自底向上)
for i in range(size - 1, 0, -1):
left_node = tree[i << 1]
right_node = tree[i << 1 | 1]
# 打包后,直接比较即可获得最高价格及其最左位置
tree[i] = left_node if left_node >= right_node else right_node
# 3. 单调栈 + 区间最值查询
stk = []
max_window = 0
# 性能优化:缓存方法引用
h_get = h.__getitem__
stk_pop = stk.pop
stk_append = stk.append
# 遍历每个价格,将其作为潜在买入点或卖出边界
for i in range(n + 1):
# 哨兵值:0 (所有股价 >= 1),用于在结束时清空栈
cur_p = h_get(i) if i < n else 0
# 当当前价格破坏了栈顶价格作为最小值的唯一性时
while stk and h_get(stk[-1]) >= cur_p:
l_idx = stk_pop()
# 在统治区间 [l_idx, i-1] 内寻找最高价的位置
# 迭代式区间查询
ql, qr = l_idx + size, (i - 1) + size
res = 0
while ql <= qr:
if ql & 1:
if tree[ql] > res: res = tree[ql]
ql += 1
if not (qr & 1):
if tree[qr] > res: res = tree[qr]
qr -= 1
ql >>= 1
qr >>= 1
# 盈利验证:卖出价必须严格大于买入价
if res:
found_price = res >> 21
if found_price > h_get(l_idx):
# 还原索引: max_pos = size - (低21位)
max_pos = size - (res & 0x1FFFFF)
length = max_pos - l_idx + 1
if length > max_window:
max_window = length
if i < n:
stk_append(i)
# 4. 输出结果
sys.stdout.write(str(max_window) + '\n')
if __name__ == '__main__':
solve()关键优化点:
- 内存分配:
array.array将 100 万个整数的占用从 28MB 降低到 4MB。线段树数组(tree)占用约 16MB。总体基础内存开销约 25MB,加上 Python 运行时和输入解析,能够稳定在 128MB 以内。 - 位运算打包:通过
(price << 21) | (size - i),我们不需要存储复杂的结构体。在比较时,价格高者胜;价格相同时,由于size - i越大代表i越小,因此自动选择了最左侧的索引。 - 查询效率:迭代式线段树查询避免了递归,是 Python 在百万级数据下执行区间查询最快的手段。
- 唯一性保证:单调栈中使用
>=弹出,保证了买入价是该区间唯一的最小值。线段树查询最左侧最大值,保证了 是区间唯一的最大值(如果存在多个最大值,选最左侧的那个,窗口内就不会包含其他等值点)。
这段代码之所以看起来“深奥”,是因为为了在 Python 中通过 100万数据量 和 1秒时间限制,它使用了竞赛编程中非常硬核的迭代式线段树(Z-tree)和位运算打包(Bit Packing)技术。
下面我为你逐行拆解,把这些“黑科技”翻译成易懂的逻辑:
size = 1 << (n - 1).bit_length()
- 作用:找到大于等于
的最小的 2的幂。 - 为什么要这么做? 传统的线段树是递归的,在 Python 中极慢。迭代式线段树要求叶子节点的数量最好是 2 的幂。
- 举例:如果
, (n-1).bit_length()是 4(的二进制是 1001,长度为4),1 << 4就是 16。- 结构:这样线段树数组的前半部分(索引
到 )是分支节点,后半部分(索引 到 )正好对应我们的原始数据。
- 位运算打包:
(h[i] << 21) | (size - i)这是为了提速而使用的最关键技巧。
- 痛点:线段树不仅要存最高价格,还要存价格相同时最靠左的下标。在 Python 中存元组
(price, index)会产生大量对象,导致内存爆炸且速度极慢。- 方案:把两个数塞进一个 64 位整数里。
- 高位(价格):左移 21 位(因为
,移 21 位足够留出空间)。比较大小时,价格高的数整体就大。 - 低位(下标处理):题目要求如果最高价有多个,我们要“严格完美”。其实为了窗口尽可能长,我们希望找最左边的下标。我们存
size - i。- 妙处:当价格相同时,比较低位。由于
i越小,size - i就越大。所以max操作会自动选出价格最高且下标最左的那个点。
- 线段树构建:
for i in range(size - 1, 0, -1)
- 逻辑:这是自底向上的。节点
i的两个孩子是2i和2i+1(即i << 1和i << 1 | 1)。- 操作:
tree[i] = left if left >= right else right。父节点直接继承那个“价格更高且更靠左”的孩子。
- 迭代查询:
while ql <= qr这是线段树最难懂的地方,它是从叶子节点向上爬的:
ql和qr:初始指向我们要查询的区间。 if ql & 1:如果ql是右孩子,说明它的左兄弟不在查询范围内,单独处理它,然后ql++移到右边的块。if not (qr & 1):如果qr是左孩子,说明它的右兄弟不在查询范围内,单独处理它,然后qr--移到左边的块。>>= 1:两人同时向上爬一级。- 优点:完全没有递归,只有极快的位运算和简单的循环。
- 单调栈与区间的关系
pythonwhile stk and h_get(stk[-1]) >= cur_p: l_idx = stk_pop() # 查询区间为 [l_idx, i-1]
- 为什么是这个区间?
- 当
h[i]出现并导致stk[-1](即l_idx)被弹出时,意味着:
- 在
l_idx的左边,最近的它的数是现在栈中新的栈顶。 - 在
l_idx的右边,第一个它的数就是当前的 i。- 所以,以
l_idx为买入点的唯一最小值统治区正好就是[l_idx, i-1]。- 动作:我们在这个统治区里,用线段树查最高价的位置。
- 最后的数据还原
pythonfound_price = res >> 21 max_pos = size - (res & 0x1FFFFF)
- 查询结果
res是个大整数。- 右移 21 位还原出最高价格。
- 低 21 位取反(用
size减去它)还原出下标。总结
这段代码其实是用C语言的思维在写 Python:
- 线段树保证了
查区间最值。 - 单调栈保证了
遍历所有可能的买入点。 - 位运算打包保证了不用创建对象,节省内存。
- 迭代写法规避了 Python 递归慢的硬伤。
这种写法虽然牺牲了一点可读性,但它是 Python 处理百万级数据、挑战 1 秒时限的“终极形态”。