M1123.最深叶节点的最近公共祖先
dfs, https://leetcode.cn/problems/lowest-common-ancestor-of-deepest-leaves/
给你一个有根节点 root 的二叉树,返回它 最深的叶节点的最近公共祖先 。
回想一下:
- 叶节点 是二叉树中没有子节点的节点
- 树的根节点的 深度 为
0,如果某一节点的深度为d,那它的子节点的深度就是d+1 - 如果我们假定
A是一组节点S的 最近公共祖先,S中的每个节点都在以A为根节点的子树中,且A的深度达到此条件下可能的最大值。
示例 1:
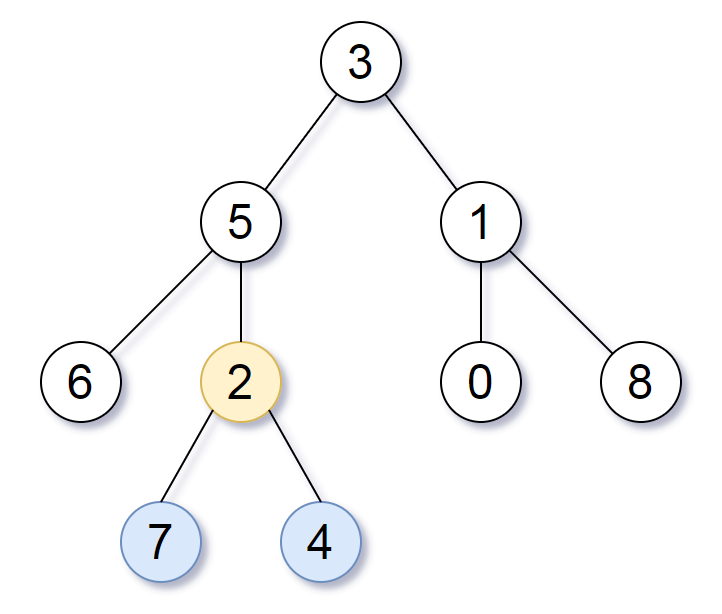
输入:root = [3,5,1,6,2,0,8,null,null,7,4]
输出:[2,7,4]
解释:我们返回值为 2 的节点,在图中用黄色标记。
在图中用蓝色标记的是树的最深的节点。
注意,节点 6、0 和 8 也是叶节点,但是它们的深度是 2 ,而节点 7 和 4 的深度是 3 。示例 2:
输入:root = [1]
输出:[1]
解释:根节点是树中最深的节点,它是它本身的最近公共祖先。示例 3:
输入:root = [0,1,3,null,2]
输出:[2]
解释:树中最深的叶节点是 2 ,最近公共祖先是它自己。提示:
- 树中的节点数将在
[1, 1000]的范围内。 0 <= Node.val <= 1000- 每个节点的值都是 独一无二 的。
注意:本题与力扣 865 重复:https://leetcode-cn.com/problems/smallest-subtree-with-all-the-deepest-nodes/
这个问题与“236. 二叉树的最近公共祖先”非常相似,但核心区别在于我们需要先找到深度最大的那些叶子节点,然后再找它们的最近公共祖先。
解题思路:后序遍历(递归)
我们可以定义一个递归函数,让它返回两个信息:
以当前节点为根的子树的最大深度。
该子树中最深叶节点的最近公共祖先。
递归逻辑如下:
对于当前节点
root:获取子树信息:
- 递归获取左子树的最大深度
left_depth和对应的 LCAleft_lca。 - 递归获取右子树的最大深度
right_depth和对应的 LCAright_lca。
- 递归获取左子树的最大深度
比较深度并判断:
- 如果
left_depth == right_depth: 说明当前节点root的左右子树中都有“最深”的叶子。那么,对于以root为根的这棵子树来说,所有的最深叶子的最近公共祖先就是root本身。其深度为left_depth + 1。 - 如果
left_depth > right_depth: 说明最深的叶子全都分布在左子树中。因此,这棵子树的最近公共祖先就是left_lca。其深度为left_depth + 1。 - 如果
right_depth > left_depth: 说明最深的叶子全都分布在右子树中。因此,这棵子树的最近公共祖先就是right_lca。其深度为right_depth + 1。
- 如果
代码实现
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
# 定义递归函数,返回 (当前子树的最大深度, 当前子树最深叶子的LCA)
def dfs(node):
if not node:
return 0, None
left_depth, left_lca = dfs(node.left)
right_depth, right_lca = dfs(node.right)
# 情况1:左右子树深度一样
# 说明当前节点就是目前发现的最深叶子们的共同祖先
if left_depth == right_depth:
return left_depth + 1, node
# 情况2:左边更深
# 最近公共祖先一定在左子树里
if left_depth > right_depth:
return left_depth + 1, left_lca
# 情况3:右边更深
# 最近公共祖先一定在右子树里
else:
return right_depth + 1, right_lca
# 运行 DFS,只取结果中的 LCA 节点部分
max_depth, lca = dfs(root)
return lca复杂度分析
- 时间复杂度:
,其中 是二叉树的节点数。每个节点被访问一次。 - 空间复杂度:
,其中 是二叉树的高度。这是递归栈所需的空间。在最坏情况下(树呈链状),空间复杂度为 ;在平衡二叉树的情况下,空间复杂度为 。
为什么这个方法有效?
这种方法巧妙地利用了深度递增的过程。在递归回溯的过程中,只有当左右两边的“最深深度”相等时,才会向上更新公共祖先节点。如果一边的深度大于另一边,说明较浅的那一边的叶子节点根本不属于“全树最深”的范畴,因此直接抛弃浅的那边,继续沿用深的那边传递上来的 LCA 即可。
O(n) 时间 + O(h) 空间。 一次 DFS 同时返回 (深度, 节点),不用存路径。
对于每个节点:
- 递归得到左、右子树的最深深度与对应的“最近公共祖先”;
- 比较左右深度:
- 若左 > 右:返回左边结果;
- 若右 > 左:返回右边结果;
- 若左 == 右:返回当前节点(因为这是最深节点的公共祖先)。
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def lcaDeepestLeaves(self, root: TreeNode) -> TreeNode:
def dfs(node):
if not node:
# 返回 (深度, LCA) 元组
return (0, None)
left_depth, left_lca = dfs(node.left)
right_depth, right_lca = dfs(node.right)
if left_depth > right_depth:
# 更深的子树在左子树
return (left_depth + 1, left_lca)
elif right_depth > left_depth:
# 更深的子树在右子树
return (right_depth + 1, right_lca)
else:
# 左右子树深度相同,当前节点是LCA
return (left_depth + 1, node)
_, lca = dfs(root)
return lca
# 辅助函数保持不变
def list_to_tree(lst, index=0):
if index >= len(lst) or lst[index] is None:
return None
root = TreeNode(lst[index])
root.left = list_to_tree(lst, 2 * index + 1)
root.right = list_to_tree(lst, 2 * index + 2)
return root
def tree_to_list(root):
if not root:
return []
queue = [root]
result = []
while queue:
node = queue.pop(0)
if node:
result.append(node.val)
queue.append(node.left)
queue.append(node.right)
else:
result.append(None)
# 去除末尾的None
while result and result[-1] is None:
result.pop()
return result
# 示例测试
if __name__ == "__main__":
solution = Solution()
# 示例 1
root1 = list_to_tree([3, 5, 1, 6, 2, 0, 8, None, None, 7, 4])
lca1 = solution.lcaDeepestLeaves(root1)
print(lca1.val) # 输出应为2
# 示例 2
root2 = list_to_tree([1])
lca2 = solution.lcaDeepestLeaves(root2)
print(lca2.val) # 输出应为1
# 示例 3
root3 = list_to_tree([0, 1, 3, None, 2])
lca3 = solution.lcaDeepestLeaves(root3)
print(lca3.val) # 输出应为2
# 额外测试
# 构建一个更复杂的树进行测试
# 1
# / \
# 2 3
# / \
# 4 5
# /
# 6
root4 = list_to_tree([1, 2, 3, 4, None, 5, None, 6])
lca4 = solution.lcaDeepestLeaves(root4)
print(lca4.val)解释
递归函数 dfs:
- 对于每个节点,递归地计算其左子树和右子树的深度及对应的 LCA。
- 如果左子树比右子树深,返回左子树的深度加一以及左子树的 LCA。
- 如果右子树比左子树深,返回右子树的深度加一以及右子树的 LCA。
- 如果左右子树深度相同,当前节点就是最深叶节点的 LCA,返回当前深度加一以及当前节点。
复杂度分析
- 时间复杂度:O(N),其中 N 是树中的节点数。每个节点只被访问一次。
- 空间复杂度:O(H),其中 H 是树的高度。递归调用栈的深度取决于树的高度。
先计算深度,再寻找 LCA。虽然是两次遍历。
这种方法逻辑非常直观:如果一个节点的左右子树高度相等,那么这个节点就是它下方所有最深叶节点的最近公共祖先。
Python 代码实现
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
# 辅助函数:计算当前节点的高度(从下往上数)
# 使用 @cache (Python 3.9+) 或字典进行记忆化,防止重复计算
@cache
def get_height(node):
if not node:
return 0
return max(get_height(node.left), get_height(node.right)) + 1
curr = root
while curr:
left_h = get_height(curr.left)
right_h = get_height(curr.right)
# 如果左右子树高度相等,说明最深叶子均匀分布在两侧(或者是叶子本身)
# 当前节点就是最近公共祖先
if left_h == right_h:
return curr
# 如果左子树更高,说明最深叶子全在左边,往左走
elif left_h > right_h:
curr = curr.left
# 如果右子树更高,往右走
else:
curr = curr.right
return curr深度解读
- 核心逻辑
- 高度(Height)定义:节点到叶子节点的最长路径。
- 判断依据:
- 如果
height(left) == height(right),意味着该节点从左路走到底和从右路走到底的深度是一样的。由于只有“最深”的叶子才是我们的目标,两侧都有最深叶子时,当前节点必然是它们的交汇点。 - 如果
height(left) > height(right),说明全局最深的叶子只可能出现在左子树中,因此 LCA 一定在左子树。
- 如果
- 复杂度分析
- 如果不使用记忆化(@cache):
- 在退化成链表的树中,时间复杂度会达到
,因为每一层都要重新计算下方所有节点的高度。
- 在退化成链表的树中,时间复杂度会达到
- 如果使用记忆化:
- 时间复杂度:
。每个节点的高度只会被计算并存储一次。之后的调用都是 。 - 空间复杂度:
。缓存需要存储 个节点的高度。
- 时间复杂度:
- 为什么这个写法更“稳”?
这种写法将“求深度”和“找祖先”两个逻辑完全解耦。在面试中,如果你无法立刻写出复杂的单次 DFS 返回多个值的逻辑,先写出这个 get_height 版本是非常稳妥的策略。
思路:回溯 + 路径对比
- 实时筛选:在回溯过程中记录当前已知的最大深度。只有当遇到更深或同深度的节点时,才记录路径,避免存储无效路径。
- 在 DFS 过程中记录,通过深度判断来更新
max_paths列表。 - 比较逻辑:所有最深叶子节点的 LCA,本质上是第一个最深叶子路径和最后一个最深叶子路径的公共前缀。
代码:
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
max_depth = -1
max_paths = []
path = []
def backtrack(node, depth):
nonlocal max_depth
if not node:
return
path.append(node)
# 到达叶子节点
if not node.left and not node.right:
if depth > max_depth:
max_depth = depth
max_paths.clear() # 发现更深的,清空之前的
max_paths.append(list(path))
elif depth == max_depth:
max_paths.append(list(path))
if node.left:
backtrack(node.left, depth + 1)
if node.right:
backtrack(node.right, depth + 1)
path.pop() # 回溯
backtrack(root, 0)
# 如果只有一条路径,直接返回该叶子节点
if len(max_paths) == 1:
return max_paths[0][-1]
# 优化:只需对比第一条和最后一条路径的公共前缀
# 因为在 DFS 中,路径是按从左到右的顺序加入的
p1, p2 = max_paths[0], max_paths[-1]
lca = root
# 比较最短的那条路径长度即可(此题中所有路径长度一致)
for i in range(len(p1)):
if p1[i] == p2[i]:
lca = p1[i]
else:
break
return lca注:此题最高效的解法通常是递归返回 `(max_depth, lca)。
【赵凌哲 光华管理学院】思路:二进制标记每个节点,这样求最近公共祖先其实就是二进制的公共前缀。
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
dic = {}
if root.left==None and root.right == None:
return root
def dfs(node, now):
dic[now] = node
if node.left:
dfs(node.left, now<<1)
if node.right:
dfs(node.right, now<<1|1)
dfs(root, 1)
deep = sorted([x for x in dic.keys() if x.bit_length() == max(dic.keys()).bit_length()])
if len(deep) == 1:
return dic[deep[-1]]
else:
return dic[deep[0]>>((deep[0]^deep[-1]).bit_length())]这个代码思路很“位运算味”,我们来一步步解读。
🧩 题目理解
题目:1123. 最深叶节点的最近公共祖先
给定一棵二叉树,找到所有最深叶节点的最近公共祖先(LCA)。
换句话说:
- 先找到最深层(depth 最大)的所有叶子;
- 再找这些叶子的最近公共祖先。
🧠 思路概述
这段代码用了一个很有创意的方法: 用二进制路径编码节点位置,然后通过二进制前缀来找公共祖先。
1️⃣ 二进制编码规则
- 根节点记为
1- 左子树记为
now << 1- 右子树记为
now << 1 | 1例如:
1(1) / \ (10)2 3(11) / \ \ (100)4 (101)5 (111)7可以看到每一层的节点路径是二进制“左移 + 加 1”的扩展。
这其实相当于记录了每个节点在一棵完全二叉树中的“位置索引”。
2️⃣ 用字典存储路径 → 节点映射
pythondic[now] = nodeDFS 遍历整棵树,把每个节点对应的二进制路径值存起来。
3️⃣ 找出最深层的叶子节点
pythonmax_depth = max(dic.keys()).bit_length() deep = [x for x in dic if x.bit_length() == max_depth]解释:
.bit_length()= 二进制位数 = 深度- 比如根是
1(1)→ 深度1 左孩子10→ 深度2101→ 深度3- 所以最深节点就是“二进制长度最长”的那些节点。
4️⃣ 如果只有一个最深节点
那它自己就是最近公共祖先:
pythonif len(deep) == 1: return dic[deep[-1]]5️⃣ 否则有多个最深叶子 → 找它们的 LCA
关键语句:
pythonreturn dic[deep[0] >> ((deep[0] ^ deep[-1]).bit_length())]这句很巧妙,我们来逐步分解:
(1)
deep[0] ^ deep[-1]
- 按位异或找出两个路径第一个不同的位置;
- 比如
100(4) 和101(5),异或得001。(2)
.bit_length()
- 这个结果的 bit_length 表示“从尾部向前,需要移掉多少位才能到公共前缀”。
(3)
deep[0] >> k
- 把路径右移
k位,去掉不同的后缀;- 得到的就是最近公共祖先的路径编号。
举个例子 🌳
1 / \ 2 3 / \ 4 5路径编号:
1: 1 2: 10 3: 11 4: 100 5: 101最深节点:
4(100)和5(101)异或:100 ^ 101 = 001bit_length = 1 右移1位:100 >> 1 = 10路径 10 对应节点2→ 正是最近公共祖先 ✅✅ 总结
步骤 思路 关键点 1 DFS 遍历整棵树 用二进制路径表示节点 2 记录路径 → 节点映射 dic[now] = node3 找最深节点(bit_length 最大) .bit_length()表示深度4 若只有一个最深叶 它自己就是 LCA 5 否则用异或求公共前缀 >> ((a^b).bit_length())⚙️ 优点与不足
优点:
- 位运算巧妙高效;
- 不需要显式记录深度和父节点。
不足:
- 依赖整数大小(若树太深可能超出 int 范围);
- 逻辑抽象,理解门槛高;
- 不易推广到非完全二叉结构的遍历方式(如有指针变化的树)。
思路:自下向上递归,在最后的叶子结点的高度设置成0,之后对于其他的节点,记录下该节点的高度,并且判定是否高度是最高的,直到左右节点的高度一样,并且同为在当前层的最大高度,这个节点就是最后要输出的节点
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
def dfs(root):
if root == None:
return 0,None
lefts,left_note = dfs(root.left)
rights,right_note = dfs(root.right)
if lefts > rights:
return lefts+1,left_note
elif lefts < rights:
return rights+1,right_note
return lefts+1,root
return dfs(root)[1]思路:记录先最大的深度,每次得到的左右子节点的深度相同时保留该节点,如果遇到有更深的节点,就对该节点更新,否则该节点就是我们要输出的节点
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
max_depth = -1
ans = None
def dfs(root,depth):
nonlocal max_depth,ans
if root == None:
max_depth = max(depth,max_depth)
return depth
lefts = dfs(root.left,depth+1)
rights = dfs(root.right,depth+1)
if lefts == rights == max_depth:
ans = root
return max(lefts,rights)
dfs(root,0)
return ans【卞知彰 物院】思路:1、先找出所有的叶子节点,然后对比长度,在最长的节点的路径中,找到第一个大家出现分歧的位置,然后输出相应节点就可以了。2、注意对于二叉树,只需要存储在这个节点是选择了想做还是向右就可以了,同时因为在回溯之外操作了path,所以需要把操作pop掉。3、注意各种指标要不要加一或者减一。
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
paths=[]
leaves=[]
def backtracking(cur,level,path):
if cur.left:
path.append('left')
backtracking(cur.left,level+1,path)
path.pop()
if cur.right:
path.append('right')
backtracking(cur.right,level+1,path)
path.pop()
if (not cur.left) and (not cur.right):
paths.append(path[:])
leaves.append(level)
backtracking(root,0,[])
max_level=max(leaves)
ans=[]
for i,p in enumerate(paths):
if leaves[i]==max_level:
ans.append(p)
common=0
for i in range(max_level):
same=True
for j in range(len(ans)):
if ans[j][i]!=ans[0][i]:
same=False
break
if not same:
break
common+=1
go=ans[0]
cur=root
for i in range(common):
if go[i]=='left':
cur=cur.left
else:
cur=cur.right
return cur