46.全排列
backtracking, https://leetcode.cn/problems/permutations/
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]示例 3:
输入:nums = [1]
输出:[[1]]提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
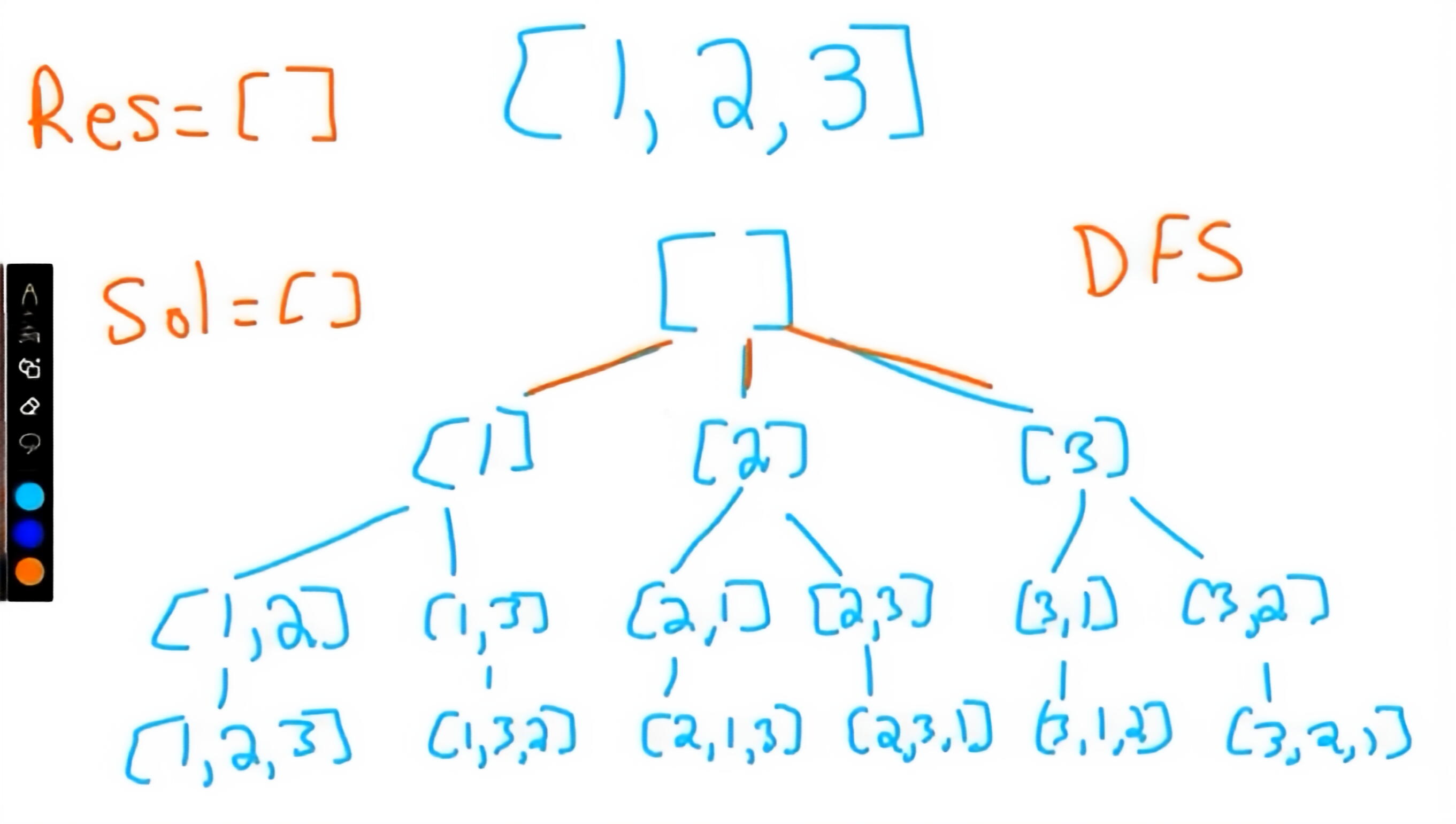
思路:递归 + 回溯
使用一个临时路径 sol 记录当前排列,通过遍历原数组并跳过已选元素的方式进行搜索。当路径长度等于数组长度时,将当前排列加入结果集。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
ans, sol = [], []
def backtrack():
# 终止条件:当前排列已满
if len(sol) == n:
ans.append(sol[:]) # 深拷贝
return
# 尝试每个未被使用的数
for x in nums:
if x not in sol: # 剪枝:避免重复使用
sol.append(x) # 选择
backtrack() # 递归
sol.pop() # 回溯
backtrack()
return ans全排列视频讲解:https://pku.instructuremedia.com/embed/c76751c9-bc0e-49f1-8a99-624b955de668
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
ans = []
def back(num_list:List[int],ans_list):
if not num_list:
ans.append(ans_list)
return
for i in range(len(num_list)):
back(num_list[:i]+num_list[i+1:],ans_list+[num_list[i]])
back(nums,[])
return ans思路:原地交换(经典回溯)
固定一个位置,然后让后面的元素依次交换过来。避免切片、减少内存拷贝,性能更好。
参数传递:在递归调用中使用可变对象(如列表)作为默认参数是一个常见的Python陷阱,因为默认参数在函数定义时只初始化一次。这意味着所有递归调用共享同一个
perm列表,这可能导致意外的行为。解决方案是不在函数参数中设置可变默认值。遍历索引而非元素:在当前实现中,你在递归过程中遍历了
nums来查找未使用的数字。更有效的方法是直接遍历当前索引到数组末尾的范围,并通过交换元素的位置来避免重复选择已经固定的数字。
from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def backtrack(first=0):
# 所有数都填完了,触发记录
if first == n:
ans.append(nums[:])
for i in range(first, n):
# 动态维护数组
nums[first], nums[i] = nums[i], nums[first]
# 继续递归填下一个数
backtrack(first + 1)
# 撤销操作
nums[first], nums[i] = nums[i], nums[first]
n = len(nums)
ans = []
backtrack()
return ans思路:把k-1阶的全排列的每一个间隔加入第k个数
# 刘中和 24工学院
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def backtrack(k):
if k==1:
return [[nums[0]]]
ans=[]
for x in backtrack(k-1):
for y in range(k):
ans.append(x[:y]+[nums[k-1]]+x[y:])
return ans
return backtrack(len(nums))from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
ans = []
visited = [False] * n # 用于标记 nums 中的元素是否被访问过
def dfs(a):
if len(a) == n:
ans.append(a[:]) # 收集当前排列
return
for i in range(n):
if visited[i]: # 跳过已访问的元素
continue
visited[i] = True
a.append(nums[i])
dfs(a)
a.pop() # 回溯
visited[i] = False
dfs([])
return ans
if __name__ == "__main__":
sol = Solution()
print(sol.permute([1, 2, 3]))隐式回溯写法
from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
ans = []
def dfs(a, remaining):
if len(a) == n:
ans.append(a[:]) # 收集当前排列
return
for i in range(len(remaining)):
# 选择 remaining[i] 并递归
dfs(a + [remaining[i]], remaining[:i] + remaining[i+1:])
dfs([], nums)
return ans
if __name__ == "__main__":
sol = Solution()
print(sol.permute([1, 2, 3]))from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
ans = []
def dfs(path, remaining):
if len(path) == n:
ans.append(path)
return
for i in range(len(remaining)):
# 选择当前元素
new_path = path + [remaining[i]]
new_remaining = remaining[:i] + remaining[i+1:]
# 递归调用
dfs(new_path, new_remaining)
dfs([], nums)
return ans
if __name__ == "__main__":
sol = Solution()
print(sol.permute([1, 2, 3]))撤销选择: 由于我们在每次递归调用时创建了新的路径和剩余元素,所以不需要显式地撤销选择。递归返回后,自动恢复到之前的状态。
from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
# https://github.com/python/cpython/blob/main/Modules/itertoolsmodule.c
def permutations(iterable, r=None):
# permutations('ABCD', 2) --> AB AC AD BA BC BD CA CB CD DA DB DC
# permutations(range(3)) --> 012 021 102 120 201 210
pool = tuple(iterable)
n = len(pool)
r = n if r is None else r
if r > n:
return
indices = list(range(n))
cycles = list(range(n, n - r, -1)) # [n, n-1, ..., n-r+1],用于控制排列的生成
yield tuple(pool[i] for i in indices[:r])
while n:
for i in reversed(range(r)):
cycles[i] -= 1
if cycles[i] == 0:
indices[i:] = indices[i + 1:] + indices[i:i + 1]
cycles[i] = n - i
else:
j = cycles[i]
indices[i], indices[-j] = indices[-j], indices[i]
yield tuple(pool[i] for i in indices[:r])
break
else:
return
return list(map(list, permutations(nums)))
if __name__ == "__main__":
sol = Solution()
print(sol.permute([1, 2, 3]))Heap’s Algorithm(用于生成排列的一种方法)的变种,核心思想是利用循环变量
cycles控制索引indices,不断交换元素来生成所有排列。我们来详细拆解它的逻辑:代码逐行解析
pythonwhile n: # 只要 n > 0,就继续循环
n是nums的长度,表示输入元素的个数。- 这个
while主要是为了保持for循环能够继续执行,实际终止条件在for内部。(1)
for i in reversed(range(r))pythonfor i in reversed(range(r)): # 从后往前遍历 cycles
reversed(range(r))代表从r-1到0递减遍历。r是排列的长度(等于n,即全排列)。- 遍历的目标是找到最右侧可以改变的位置,从而生成下一个排列。
(2) 递减
cycles[i]pythoncycles[i] -= 1
cycles[i]记录了当前索引i还可以切换多少次。- 每次
cycles[i]递减 1,意味着它朝着终止状态前进。(3) 处理
cycles[i] == 0的情况pythonif cycles[i] == 0: indices[i:] = indices[i + 1:] + indices[i:i + 1] # 右移 indices[i] cycles[i] = n - i
- 如果
cycles[i]变成0,意味着indices[i]的所有可能排列已经遍历完了,我们需要重置cycles[i],并改变indices顺序:
indices[i:] = indices[i + 1:] + indices[i:i + 1]
- 效果:把
indices[i]向右移动,让indices[i]参与新的排列。- 示例:
pythonindices = [0, 1, 2] # i = 1 时,如果 indices = [0, 1, 2] indices[1:] = indices[2:] + indices[1:2] # -> [2] + [1] = [2, 1] # 结果变成 [0, 2, 1],相当于把 indices[1] 右移cycles[i] = n - i
- 重新初始化
cycles[i],让它可以继续切换排列。(4) 交换
indices[i]和indices[-j]pythonelse: j = cycles[i] # 取当前 cycles[i] 的值 indices[i], indices[-j] = indices[-j], indices[i] # 交换索引 yield tuple(pool[i] for i in indices[:r]) # 生成新排列 break # 关键!生成新排列后,跳出 for-loop,重新进入 while 循环
交换
indices[i]和indices[-j]:
indices[-j]代表从后往前数的第j个元素。- 这样保证了排列是按字典序依次生成的。
- 示例:
python# 初始 indices = [0, 1, 2] cycles = [3, 2, 1] # 初始状态 # 交换发生在 i=1 且 j=1 indices[1], indices[-1] = indices[-1], indices[1] # indices 变成 [0, 2, 1](因为 indices[-1] 其实是 indices[2])
yield生成新排列:
- 通过
yield产出新的排列,每次都把indices[:r]映射到pool,确保返回的值是正确的元素顺序。
break关键作用:
- 一旦找到一个可以交换的位置,就跳出
for,回到while n,开始新的排列。- 如果不
break,代码会继续尝试i更小的索引,导致重复计算。(5)
else: return(当for循环完整遍历后终止)pythonelse: return
- 如果
for i in reversed(range(r))没有执行break,说明所有cycles[i]都归零,意味着所有排列已生成完毕,此时直接return终止while循环。完整执行示例
我们用
nums = [1, 2, 3]详细跟踪indices和cycles的变化:初始状态
pythonnums = [1, 2, 3] pool = (1, 2, 3) # 将 nums 转为元组 n = 3, r = 3 indices = [0, 1, 2] # 索引序列 cycles = [3, 2, 1] # 代表每个位置还能调整多少次排列生成过程
Step indices 生成的排列 cycles 说明 1 [0, 1, 2] [1, 2, 3] [3, 2, 1] 初始排列 2 [0, 2, 1] [1, 3, 2] [3, 2, 0] cycles[2] = 0,调整 indices3 [2, 0, 1] [3, 1, 2] [3, 1, 1] cycles[1] -= 1,交换 indices[1]4 [2, 1, 0] [3, 2, 1] [3, 1, 0] cycles[2] = 0,调整 indices5 [1, 2, 0] [2, 3, 1] [3, 0, 1] cycles[1] = 0,调整 indices6 [1, 0, 2] [2, 1, 3] [3, 0, 0] cycles[2] = 0,调整 indices7 [0, 1, 2] - [3, 2, 1] 全部遍历完毕,退出 最终返回:
python[[1, 2, 3], [1, 3, 2], [3, 1, 2], [3, 2, 1], [2, 3, 1], [2, 1, 3]]总结
核心逻辑:
- 通过
cycles[i]控制每个位置还能变换多少次。- 通过
indices交换元素生成新的排列。- 通过
break保证每次while只生成一个新排列。Heap’s Algorithm 变种:
cycles控制排列顺序。indices记录当前排列的索引。yield逐步生成排列,避免一次性占用大量内存。时间复杂度:
- O(n!)(必须遍历所有排列)。
- 空间复杂度 O(n)(存储
indices和cycles)。你可以尝试手动模拟
indices变化,这样能更深刻理解这个while循环的工作方式!
Q:Heap’s Algorithm能直白一点讲清楚吗?
当然!Heap’s Algorithm 是一种 高效生成排列 的算法,特点是每次交换元素,生成下一个排列,避免重复计算。它的核心思想是:
- 固定前面的部分,交换后面的元素,这样就能依次生成所有可能的排列。
- 利用索引
indices记录当前排列,每次交换后输出新的排列。- 循环控制
cycles,决定如何交换,保证所有排列都能被遍历到。Heap’s Algorithm 直白解释
假设你有 3 个数
[1, 2, 3],想生成所有排列,Heap’s Algorithm 的步骤如下:1. 先假设第一个数不变,调整后面的
[1, 2, 3]✅(原始顺序)[1, 3, 2]✅(交换 最后两个)2. 交换第一个数和其他数
[2, 3, 1]✅(交换 1 和 2)[2, 1, 3]✅(再调整后面的)3. 交换第一个数和最后一个数
[3, 1, 2]✅(交换 1 和 3)[3, 2, 1]✅(再调整后面的)最终生成所有 6 种排列:
[1, 2, 3] [1, 3, 2] [2, 3, 1] [2, 1, 3] [3, 1, 2] [3, 2, 1]可以看到,每次交换的都是相邻或者靠近的位置,这样可以高效遍历所有可能的排列。
Heap’s Algorithm 关键规则
- 如果是偶数次交换(如
n = 2, 4, 6,...),交换第0个元素和第n-1个元素。- 如果是奇数次交换(如
n = 3, 5, 7,...),交换第i个元素和最后一个元素。- 重复这个过程,直到所有排列都生成。
举个简单例子:用 Heap’s Algorithm 生成
[A, B, C]的所有排列
步骤 交换操作 结果 1 初始排列 A B C2 交换 B和CA C B3 交换 A和CC A B4 交换 A和BC B A5 交换 C和BB C A6 交换 B和AB A C最终输出:
A B C A C B C A B C B A B C A B A C这就是 Heap’s Algorithm 的基本逻辑!
Heap’s Algorithm 适合什么情况?
- 需要生成所有排列(效率比暴力法高)。
- 想要不占用太多内存(用
yield逐步生成)。- 数据规模适中(n <= 10),因为排列数量是
n!,当n很大时会爆炸性增长。如果你需要一个更简单的方法,可以直接用 Python 内置的
itertools.permutations:pythonfrom itertools import permutations print(list(permutations([1, 2, 3])))但理解 Heap’s Algorithm 能帮助你更深入掌握排列生成的核心原理!🚀
Q: 这个简单的例子[A,B,C],如何对应到这段代码?
while n:
for i in reversed(range(r)):
cycles[i] -= 1
if cycles[i] == 0:
indices[i:] = indices[i + 1:] + indices[i:i + 1]
cycles[i] = n - i
else:
j = cycles[i]
indices[i], indices[-j] = indices[-j], indices[i]
yield tuple(pool[i] for i in indices[:r])
break
else:
return让我们一步步将 Heap’s Algorithm 在
[A, B, C]上的执行过程对应到代码中的while n结构,这样你就能清楚它是如何运作的。代码核心变量解释
pythonpool = ('A', 'B', 'C') # 输入的元素 n = len(pool) = 3 # 共有 3 个元素 r = n # 生成全排列 indices = [0, 1, 2] # 记录当前排列的索引 cycles = [3, 2, 1] # 控制每个位置还能切换多少次代码结构解析
pythonwhile n: # 只要 n > 0,就不断生成排列 for i in reversed(range(r)): # 从后往前遍历 cycles cycles[i] -= 1 # 递减 cycles[i],控制当前索引还能变换几次
cycles控制某个位置的索引还能变化几次,如果cycles[i] == 0,表示这个位置已经穷尽,需要调整索引。pythonif cycles[i] == 0: indices[i:] = indices[i + 1:] + indices[i:i + 1] # 右移 indices[i] cycles[i] = n - i # 重新初始化 cycles[i]
- 如果
cycles[i]归零,说明indices[i]的所有可能已经用完,把indices[i]右移,并重置cycles[i]。pythonelse: j = cycles[i] # 获取当前 cycles[i] 计数 indices[i], indices[-j] = indices[-j], indices[i] # 交换 indices[i] 和 indices[-j] yield tuple(pool[i] for i in indices[:r]) # 生成新的排列 break # 只改变一次排列后,跳出 for 重新进入 while
- 如果
cycles[i]还没用完,就交换indices[i]和indices[-j],然后yield生成新的排列。对照
[A, B, C]执行过程初始状态
pythonindices = [0, 1, 2] # 初始索引顺序 cycles = [3, 2, 1] # 初始 cycles 计数我们用
indices来访问pool,最初:[A, B, C]此时
indices = [0, 1, 2],所以pool[0] = A, pool[1] = B, pool[2] = C。Step 1: 初始排列
pythonyield tuple(pool[i] for i in indices[:r]) # 生成 (A, B, C)✅ 输出:
[A, B, C]Step 2: 交换
C和B
cycles[2] -= 1变成0,进入if cycles[i] == 0分支:pythonindices[2:] = indices[3:] + indices[2:3] # indices[2] 右移但
indices[3:]为空,因此只是保持[0, 1, 2]不变。重新初始化
cycles[2] = 1。继续循环,
cycles[1] -= 1变成1,进入else分支:pythonj = cycles[1] = 1 indices[1], indices[-1] = indices[-1], indices[1] # 交换 B 和 C
indices = [0, 2, 1],对应pool = [A, C, B]。✅ 输出:
[A, C, B]Step 3: 交换
A和C
cycles[2] -= 1变成0,重新初始化cycles[2] = 1。
cycles[1] -= 1变成0,进入if cycles[i] == 0:pythonindices[1:] = indices[2:] + indices[1:2] # indices[1] 右移变成
indices = [2, 0, 1],即pool = [C, A, B]。重新初始化
cycles[1] = 2。✅ 输出:
[C, A, B]Step 4: 交换
A和B
cycles[2] -= 1变成0,重新初始化cycles[2] = 1。
cycles[1] -= 1变成1,进入else:pythonj = cycles[1] = 1 indices[1], indices[-1] = indices[-1], indices[1] # 交换 A 和 B变成
indices = [2, 1, 0],即pool = [C, B, A]。✅ 输出:
[C, B, A]Step 5: 交换
C和B
cycles[2] -= 1变成0,重新初始化cycles[2] = 1。
cycles[1] -= 1变成0,进入if cycles[i] == 0:pythonindices[1:] = indices[2:] + indices[1:2] # indices[1] 右移变成
indices = [1, 2, 0],即pool = [B, C, A]。重新初始化
cycles[1] = 2。✅ 输出:
[B, C, A]Step 6: 交换
B和A
cycles[2] -= 1变成0,重新初始化cycles[2] = 1。
cycles[1] -= 1变成1,进入else:pythonj = cycles[1] = 1 indices[1], indices[-1] = indices[-1], indices[1] # 交换 B 和 A变成
indices = [1, 0, 2],即pool = [B, A, C]。✅ 输出:
[B, A, C]终止条件
当所有
cycles归零时,for循环完成,触发else: return终止while n,生成排列结束。完整输出
[A, B, C] [A, C, B] [C, A, B] [C, B, A] [B, C, A] [B, A, C]这正是
3! = 6个全排列。总结
cycles递减 控制排列变换次数。indices交换元素,让不同元素出现在不同位置。if cycles[i] == 0右移indices[i],确保每个位置的元素被遍历。else交换indices[i]和indices[-j],改变排列顺序。break让while继续循环,确保逐个生成排列,而不是一次性生成所有。这样,你就可以完全理解这段
while代码是如何按照 Heap’s Algorithm 生成排列的了!💡