M131.分割回文串
dp, backtracking, https://leetcode.cn/problems/palindrome-partitioning/
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串。返回 s 所有可能的分割方案。回文串是指向前和向后读都相同的字符串。
示例 1:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]示例 2:
输入:s = "a"
输出:[["a"]]提示:
1 <= s.length <= 16s仅由小写英文字母组成
【陈林鑫 物理学院】思路:
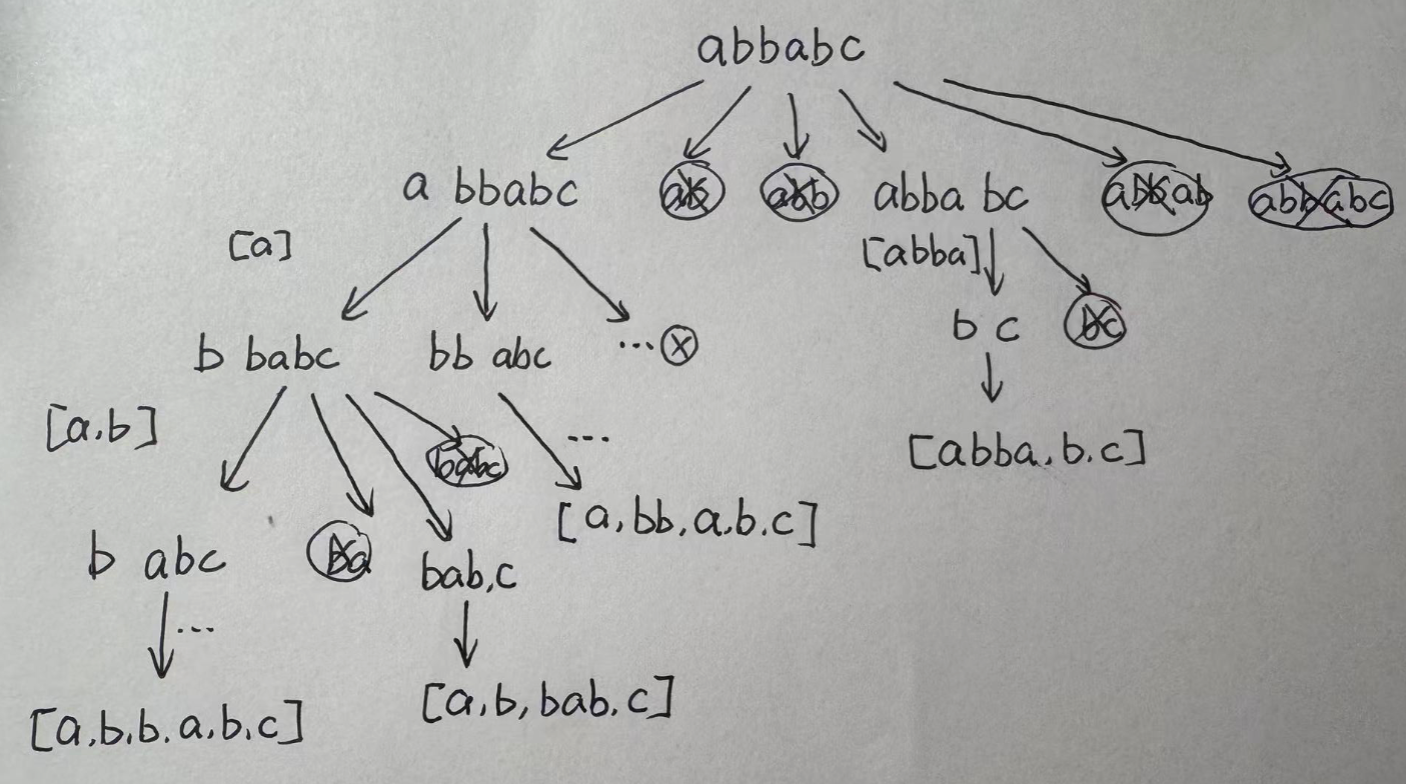
如图所示,对于一个字符串s,依次判断从i=1到i=len(s)+1,s[0:i]是否为回文串,如果是,则在i处分割,前半部分为回文串,将它计入这条递归的列表resi中,剩下的部分s[i:]则继续分割。如果剩下的字符串s[i:]长度为0,则说明分割完毕,返回resi。for循环可以遍历所有情形。
class Solution:
def partition(self, s: str) -> List[List[str]]:
n = len(s)
ans, sol = [], []
def backtrack(i):
if i == n:
ans.append(sol[:])
return
for end in range(i+1, n+1):
substr = s[i:end]
if substr == substr[::-1]:
sol.append(substr)
backtrack(end)
sol.pop()
backtrack(0)
return ansclass Solution:
def partition(self, s: str) -> List[List[str]]:
def is_palindrome(sub):
return sub == sub[::-1]
def backtrack(start, path):
if start == len(s):
res.append(path[:])
return
for end in range(start + 1, len(s) + 1):
if is_palindrome(s[start:end]):
path.append(s[start:end])
backtrack(end, path)
path.pop()
res = []
backtrack(0, [])
return resclass Solution:
def partition(self, s: str) -> List[List[str]]:
ans = []
def divide(ans_list,word):
if len(word) == 0:
ans.append(ans_list)
return
for i in range(1,len(word)+1):
if word[:i] == word[:i][::-1]:
divide(ans_list+[word[:i]],word[i:])
divide([],s)
return ansclass Solution:
def partition(self, s: str) -> List[List[str]]:
def is_palindrome(s):
return s == s[::-1]
def backtracking(start, path):
if start == len(s):
res.append(path)
return
for i in range(start, len(s)):
if is_palindrome(s[start:i+1]):
backtracking(i+1, path + [s[start:i+1]])
res = []
backtracking(0, [])
return res第一部分的判断某一段子串是不是回文串的 dp 写法;第二部分是 dfs 找切片。其中第一部分的 dp 的值都是布尔值,这样方便后续判断某一个子串是不是回文串;第二部分应该是双指针的思路,用 i 来遍历所有起点,用 j 来从每一个起点开始遍历第一处断点,这种写法也值得积累。
is_palindrome 这个二维表的“右上三角”部分,是“按列生成”的。 也就是说,它是一列一列(固定 right 列,遍历所有 left 行)地被计算出来的。
class Solution:
def partition(self, s: str) -> List[List[str]]:
n = len(s)
# 预处理回文子串
is_palindrome = [[False] * n for _ in range(n)]
for right in range(n):
for left in range(right + 1):
if s[left] == s[right] and (right - left <= 1 or is_palindrome[left + 1][right - 1]):
is_palindrome[left][right] = True
res = []
path = []
def backtrack(start):
if start == n:
res.append(path[:]) # 复制当前路径
return
for end in range(start, n):
if is_palindrome[start][end]: # 只在是回文的地方切割
path.append(s[start:end + 1])
backtrack(end + 1)
path.pop() # 撤销选择
backtrack(0)
return res形象理解总结
is_palindrome[left][right]↔ 子串s[left:right+1]- 填表顺序:从左上往右下“扩散”
- 依赖方向:每个格子依赖左下格
(left+1, right-1) - 填的是右上三角区域
- 用这种顺序保证 DP 的正确性和完整性
【卞知彰 物理学院】思路:1、在不需要传递切片的时候就不传递切片,考虑到在不同选择的时候需要pop,所以其实path是可以共用的。这也就要注意ans需要定义在最前面。
2、可以使用动态规划的方式,提前用一个n×n的矩阵,表示s[i,j]是不是一个回文序列,以免重复判断。同时在判断回文序列的时候,不用反复对比,只需要根据内层已有的结果,再加上两端的结果。实现的时候要注意检索i和j的顺序,应该是j从0到n-1,i从j到0,这样才可以保证所有内部序列都提前被判断过。判断的时候有三种情况。最后要注意表格中i和j的含义和s[i,j]略有不同,需要小心加一。
class Solution:
def partition(self, s: str) -> List[List[str]]:
n=len(s)
ans=[]
huiwen=[[False]*n for _ in range(n)]
for j in range(n):
for i in range(j,-1,-1):
if i==j:
huiwen[i][j]=True
elif j==i+1 and s[i]==s[j]:
huiwen[i][j]=True
elif s[j]==s[i] and huiwen[i+1][j-1]:
huiwen[i][j]=True
def backtracking(start,path):
if start==n:
ans.append(path[:])
return
for i in range(start,n):
if huiwen[start][i]:
path.append(s[start:i+1])
backtracking(i+1, path)
path.pop()
backtracking(0,[])
return ansfrom typing import List
class Solution:
def partition(self, s: str) -> List[List[str]]:
n = len(s)
ans = []
# 预处理所有回文子串:huiwen[i][j] = s[i:j+1] 是否为回文
huiwen = [[False] * n for _ in range(n)]
for j in range(n):
for i in range(j + 1):
if s[i] == s[j] and (j - i < 2 or huiwen[i + 1][j - 1]):
huiwen[i][j] = True
# 回溯搜索所有分割
path = []
def dfs(start: int):
if start == n:
ans.append(path[:])
return
for end in range(start, n):
if huiwen[start][end]:
path.append(s[start:end + 1])
dfs(end + 1)
path.pop()
dfs(0)
return ans如果字符串较长,可以使用 LRU 缓存递归判断(不建 DP 表)
from functools import lru_cache
class Solution:
def partition(self, s: str) -> List[List[str]]:
n = len(s)
ans = []
@lru_cache(None)
def is_pal(i, j):
return i >= j or (s[i] == s[j] and is_pal(i + 1, j - 1))
def dfs(start, path):
if start == n:
ans.append(path[:])
return
for end in range(start, n):
if is_pal(start, end):
path.append(s[start:end + 1])
dfs(end + 1, path)
path.pop()
dfs(0, [])
return ans