M297.二叉树的序列化与反序列化
dfs, bfs, https://leetcode.cn/problems/serialize-and-deserialize-binary-tree/
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
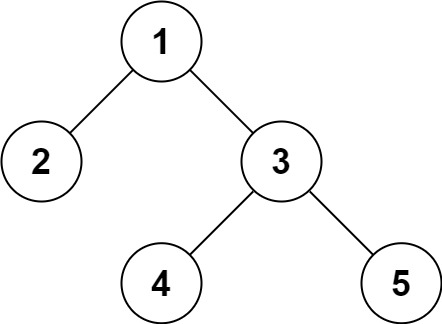
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]示例 2:
输入:root = []
输出:[]示例 3:
输入:root = [1]
输出:[1]示例 4:
输入:root = [1,2]
输出:[1,2]提示:
- 树中结点数在范围
[0, 10^4]内 -1000 <= Node.val <= 1000
这个问题要求实现二叉树的序列化(Tree -> String)与反序列化(String -> Tree)。
最常用的两种方法是 DFS(前序遍历) 和 BFS(层序遍历)。
方法一:DFS(前序遍历)
这种方法比较直观,序列化时按照“根-左-右”的顺序,遇到空节点用特殊字符(如 # 或 None)表示。反序列化时,同样按前序遍历的顺序递归构建。
代码实现:
python
class Codec:
def serialize(self, root):
"""将二叉树编码为字符串。"""
res = []
def dfs(node):
if not node:
res.append("None")
return
res.append(str(node.val))
dfs(node.left)
dfs(node.right)
dfs(root)
return ",".join(res)
def deserialize(self, data):
"""将字符串解码为二叉树。"""
data_list = data.split(",")
# 使用迭代器或全局索引来逐个读取列表元素
self.it = iter(data_list)
def build():
val = next(self.it)
if val == "None":
return None
node = TreeNode(int(val))
node.left = build() # 递归构建左子树
node.right = build() # 递归构建右子树
return node
return build()方法二:BFS(层序遍历)
这种方法与 LeetCode 题目描述中展示的格式完全一致。序列化时使用队列进行层序遍历,包括空节点。反序列化时也使用队列,依次为队列中的节点挂载左右子节点。
代码实现:
python
from collections import deque
class Codec:
def serialize(self, root):
"""将二叉树编码为字符串。"""
if not root: return ""
queue = deque([root])
res = []
while queue:
node = queue.popleft()
if node:
res.append(str(node.val))
queue.append(node.left)
queue.append(node.right)
else:
res.append("None")
return ",".join(res)
def deserialize(self, data):
"""将字符串解码为二叉树。"""
if not data: return None
nodes = data.split(",")
root = TreeNode(int(nodes[0]))
queue = deque([root])
index = 1 # 用于遍历 nodes 列表
while queue:
node = queue.popleft()
# 处理左子节点
if nodes[index] != "None":
node.left = TreeNode(int(nodes[index]))
queue.append(node.left)
index += 1
# 处理右子节点
if nodes[index] != "None":
node.right = TreeNode(int(nodes[index]))
queue.append(node.right)
index += 1
return root复杂度分析
时间复杂度:
- 序列化:
,其中 是节点数,每个节点访问一次。 - 反序列化:
,每个节点被处理一次。
- 序列化:
空间复杂度:
- DFS:
。在最坏情况下(树呈链状),递归栈的深度为 。 - BFS:
。队列在最坏情况下(完全二叉树最后一层)存储约 个节点。
总结
- DFS:
- DFS 代码更简洁,利用递归天然满足“根左右”的顺序。
- BFS 逻辑上更符合我们观察树的直觉(一层一层看),且生成的字符串格式通常更短(可以剪掉末尾不必要的空节点,虽然上面代码为了逻辑清晰没做特殊剪裁)。