M3212.统计 X 和 Y 频数相等的子矩阵数量
prefix sum, https://leetcode.cn/problems/count-submatrices-with-equal-frequency-of-x-and-y/
给你一个二维字符矩阵 grid,其中 grid[i][j] 可能是 'X'、'Y' 或 '.',返回满足以下条件的子矩阵数量:
- 包含
grid[0][0] 'X'和'Y'的频数相等。- 至少包含一个
'X'。
示例 1:
输入: grid = [["X","Y","."],["Y",".","."]]
输出: 3
解释:
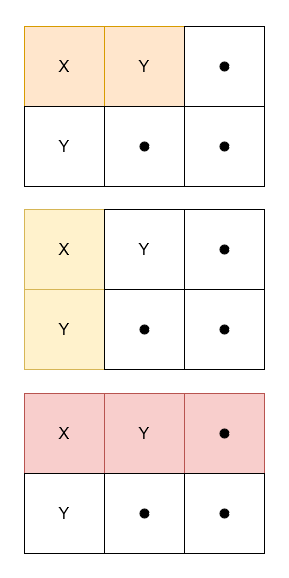
示例 2:
输入: grid = [["X","X"],["X","Y"]]
输出: 0
解释:
不存在满足 'X' 和 'Y' 频数相等的子矩阵。
示例 3:
输入: grid = [[".","."],[".","."]]
输出: 0
解释:
不存在满足至少包含一个 'X' 的子矩阵。
提示:
1 <= grid.length, grid[i].length <= 1000grid[i][j]可能是'X'、'Y'或'.'.
这个问题要求统计满足特定条件的子矩阵数量。由于所有子矩阵必须包含 grid[0][0],这意味着每一个子矩阵的左上角固定在 (0, 0),我们只需要通过枚举其右下角坐标 (i, j) 来确定所有可能的子矩阵。
算法思路
二位前缀和思想: 我们需要频繁查询从
(0, 0)到(i, j)的矩形范围内 'X' 和 'Y' 的数量。- 设
countX(i, j)为子矩阵(0,0)到(i,j)中 'X' 的数量。 - 设
countY(i, j)为子矩阵(0,0)到(i,j)中 'Y' 的数量。 - 判定条件:
countX(i, j) == countY(i, j)且countX(i, j) > 0。
- 设
递推优化: 我们可以利用前缀和的性质,在遍历矩阵的过程中动态维护这些计数。 对于每一行
r,我们维护一个当前行的累计计数rowX和rowY。 同时,我们使用一个数组colX[c]和colY[c]来存储从第 0 行到当前行,第 0 列到第c列的累计 'X' 和 'Y' 的数量。递推公式:
colX[c] (新) = colX[c] (旧) + rowX- 其中
rowX是当前行中从第 0 列到第c列的 'X' 的总数。
复杂度分析:
- 时间复杂度:
,其中 是行数, 是列数。我们只需要对矩阵进行一次全遍历。 - 空间复杂度:
,只需两个长度为列数的数组来存储列向的累计前缀和(也可以用 的二维数组,但在 的量级下 更优)。
- 时间复杂度:
代码实现
from typing import List
class Solution:
def numberOfSubmatrices(self, grid: List[List[str]]) -> int:
rows = len(grid)
cols = len(grid[0])
# colX[c] 存储子矩阵 (0,0) 到 (current_row, c) 中 'X' 的数量
# colY[c] 存储子矩阵 (0,0) 到 (current_row, c) 中 'Y' 的数量
colX = [0] * cols
colY = [0] * cols
ans = 0
for r in range(rows):
rowX = 0 # 当前行从 (r, 0) 到 (r, c) 的 'X' 计数
rowY = 0 # 当前行从 (r, 0) 到 (r, c) 的 'Y' 计数
# 获取当前行的引用,加速访问
grid_r = grid[r]
for c in range(cols):
char = grid_r[c]
# 更新当前行的计数
if char == 'X':
rowX += 1
elif char == 'Y':
rowY += 1
# 更新从 (0,0) 到 (r,c) 的总计数
# colX[c] 原本存的是 (0,0) 到 (r-1, c) 的和
colX[c] += rowX
colY[c] += rowY
# 检查条件:
# 1. 'X' 和 'Y' 频数相等
# 2. 至少包含一个 'X'
if colX[c] == colY[c] and colX[c] > 0:
ans += 1
return ans示例解析
以 示例 1 为例:grid = [["X","Y","."],["Y",".","."]]
第一行 (r=0):
c=0:rowX=1, rowY=0->colX[0]=1, colY[0]=0(不满足)c=1:rowX=1, rowY=1->colX[1]=1, colY[1]=1(满足: 1=1, 1>0) -> ans = 1c=2:rowX=1, rowY=1->colX[2]=1, colY[2]=1(满足: 1=1, 1>0) -> ans = 2
第二行 (r=1):
c=0:rowX=0, rowY=1->colX[0]=1, colY[0]=1(满足: 1=1, 1>0) -> ans = 3c=1:rowX=0, rowY=1->colX[1]=1, colY[1]=2(不满足)c=2:rowX=0, rowY=1->colX[2]=1, colY[2]=2(不满足)
最终输出
3,符合预期。