M3529.统计水平子串和垂直子串重叠格子的数目
KMP, 差分数组, https://leetcode.cn/problems/count-cells-in-overlapping-horizontal-and-vertical-substrings/
给你一个由字符组成的 m x n 矩阵 grid 和一个字符串 pattern。
水平子串 是从左到右的一段连续字符序列。如果子串到达了某行的末尾,它将换行并从下一行的第一个字符继续。不会 从最后一行回到第一行。
垂直子串 是从上到下的一段连续字符序列。如果子串到达了某列的底部,它将换列并从下一列的第一个字符继续。不会 从最后一列回到第一列。
请统计矩阵中满足以下条件的单元格数量:
- 该单元格必须属于 至少 一个等于
pattern的水平子串,且属于 至少 一个等于pattern的垂直子串。
返回满足条件的单元格数量。
示例 1:
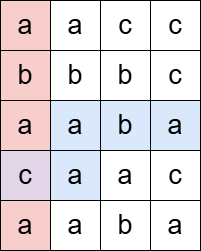
输入: grid = [["a","a","c","c"],["b","b","b","c"],["a","a","b","a"],["c","a","a","c"],["a","a","c","c"]], pattern = "abaca"
输出: 1
解释:
"abaca" 作为一个水平子串(蓝色)和一个垂直子串(红色)各出现一次,并在一个单元格(紫色)处相交。
示例 2:
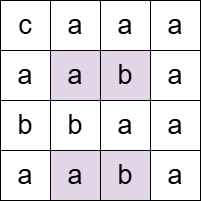
输入: grid = [["c","a","a","a"],["a","a","b","a"],["b","b","a","a"],["a","a","b","a"]], pattern = "aba"
输出: 4
解释:
上述被标记的单元格都同时属于至少一个 "aba" 的水平和垂直子串。
示例 3:
输入: grid = [["a"]], pattern = "a"
输出: 1
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 10001 <= m * n <= 10^51 <= pattern.length <= m * ngrid和pattern仅由小写英文字母组成。
下面给出一种基于 KMP(Knuth–Morris–Pratt)字符串匹配的线性时间解法。思路如下:
将矩阵展平为两个长串
- 水平串
S_h:按行从左到右、从上到下依次拼接,长度为。 - 垂直串
S_v:按列从上到下、从左到右依次拼接,长度同样为。
- 水平串
用 KMP 在两条长串上分别查找所有与
pattern完全匹配的起始位置- 得到水平匹配集合
; - 得到垂直匹配集合
。
- 得到水平匹配集合
标记所有被水平匹配覆盖的格子
- 对每个水平匹配起点
,把区间 内的所有位置都标记为 “横向有效”。
- 对每个水平匹配起点
标记所有被垂直匹配覆盖的格子
对每个垂直匹配起点
,把区间 内的所有位置都标记为 “纵向有效”。 注意:垂直串的第
个字符对应的矩阵位置为
统计同时被横向和纵向标记的格子数量
- 在矩阵视为一维下标
上统计两种标记都为 True的总数。
- 在矩阵视为一维下标
用 差分数组 替代逐字符打标,做到真正的
from typing import List
class Solution:
def countCells(self, grid: List[List[str]], pattern: str) -> int:
m, n = len(grid), len(grid[0])
L = len(pattern)
total = m * n
if L > total:
return 0
# 1. 构造水平串和垂直串
S_h = ''.join(''.join(row) for row in grid)
cols = []
for j in range(n):
for i in range(m):
cols.append(grid[i][j])
S_v = ''.join(cols)
# 2. KMP 预处理:构造 lps 数组
def build_lps(p: str) -> List[int]:
lps = [0] * len(p)
k = 0
for i in range(1, len(p)):
while k > 0 and p[k] != p[i]:
k = lps[k - 1]
if p[k] == p[i]:
k += 1
lps[i] = k
return lps
# 3. KMP 查所有匹配起点
def kmp_search(text: str, pat: str, lps: List[int]) -> List[int]:
res = []
j = 0
for i, ch in enumerate(text):
while j > 0 and pat[j] != ch:
j = lps[j - 1]
if pat[j] == ch:
j += 1
if j == len(pat):
res.append(i - j + 1)
j = lps[j - 1]
return res
lps = build_lps(pattern)
starts_h = kmp_search(S_h, pattern, lps)
starts_v = kmp_search(S_v, pattern, lps)
# 4. 用差分数组标记覆盖区间
# diff_h[i] 表示 S_h[i] 位置的“增量”,最后前缀和>0即被水平匹配覆盖
# diff_v 同理针对 S_v
diff_h = [0] * (total + 1)
diff_v = [0] * (total + 1)
for st in starts_h:
diff_h[st] += 1
diff_h[st + L] -= 1
for st in starts_v:
diff_v[st] += 1
diff_v[st + L] -= 1
# 5. 前缀和,得到覆盖标志
cov_h = [0] * total
cov_v = [0] * total
cnt = 0
s = 0
for i in range(total):
s += diff_h[i]
cov_h[i] = 1 if s > 0 else 0
s = 0
for i in range(total):
s += diff_v[i]
cov_v[i] = 1 if s > 0 else 0
# 6. 遍历每个格子,映射到 S_h 和 S_v 的下标,统计双重覆盖
ans = 0
for i in range(m):
base_h = i * n # 行首在 S_h 的下标
for j in range(n):
idx_h = base_h + j # (i,j) 在 S_h
idx_v = j * m + i # (i,j) 在 S_v
if cov_h[idx_h] and cov_v[idx_v]:
ans += 1
return ans
if __name__ == "__main__":
sol = Solution()
print(sol.countCells(
[["a", "a", "c", "c"], ["b", "b", "b", "c"], ["a", "a", "b", "a"], ["c", "a", "a", "c"], ["a", "a", "c", "c"]],
"abaca")) # Output: 1
print(sol.countCells([["c", "a", "a", "a"], ["a", "a", "b", "a"], ["b", "b", "a", "a"], ["a", "a", "b", "a"]],
"aba")) # Output: 4
print(sol.countCells([["a"]], "a")) # Output: 1复杂度分析
- 时间复杂度:
- 构造两条长度为
的串: - 构造 LPS 数组:
- 在两条串上各做一次 KMP 匹配:
- 标记和计数:
总体为 ,在 的约束下足够快。
- 构造两条长度为
- 空间复杂度:
(用于存储两条串和两个标记数组)。
这样就能线性时间内准确统计出既在某个水平匹配中又在某个垂直匹配中的所有格子数。
关键优化点
- 不再对每一次匹配都循环标记
个格子,而是对匹配区间做差分,加速到对每个匹配只做两次增/减操作。 - 最后一次遍历
的前缀和即可得到每个位置是否被覆盖。
如此整体现实